Google DeepMind has released SigLIP 2, a family of Open-weight (Apache V2) vision-language encoders trained on data covering 109 languages, including Swahili. The released models are available in four sizes: ViT-B (86M), L (303M), So400m (400M), and g (1B).
Why is this important?
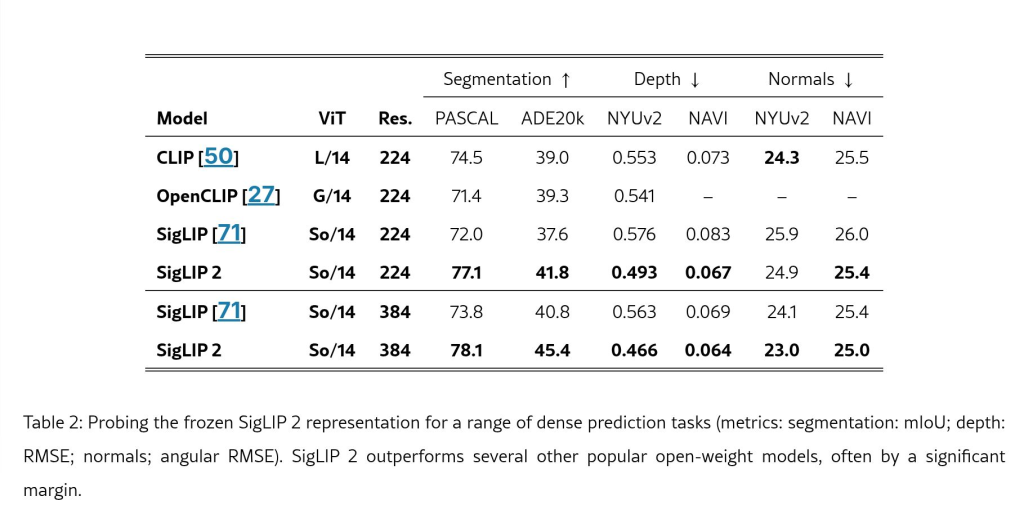
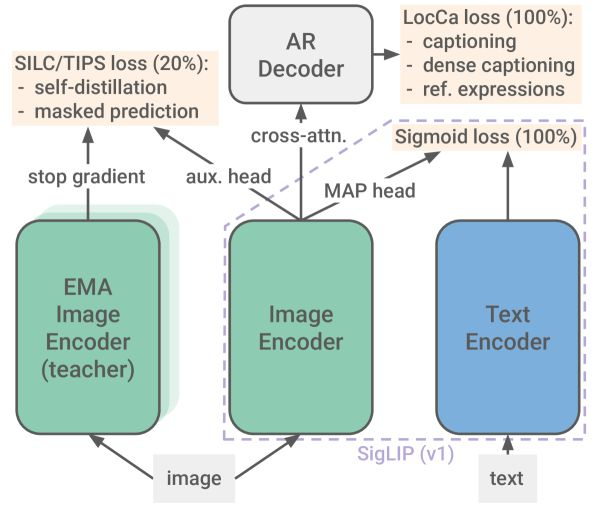
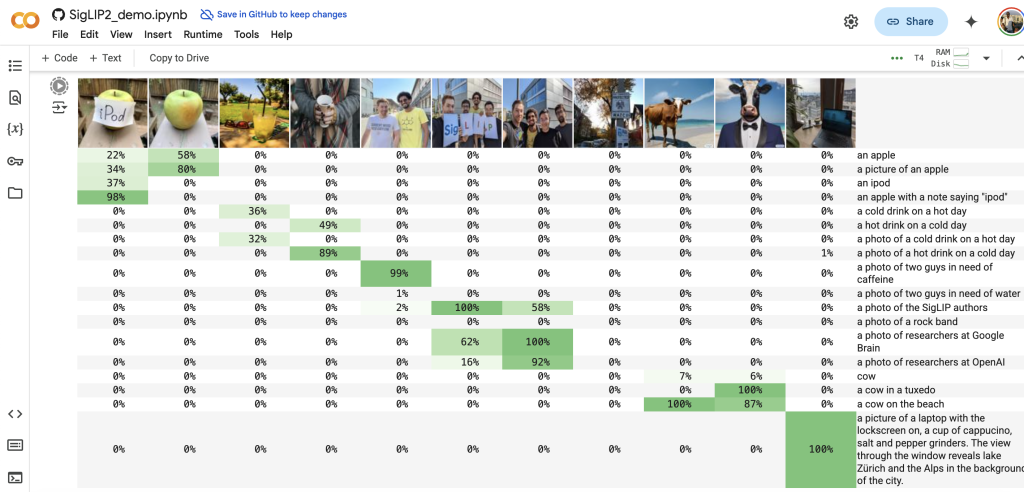
This release offers improved multilingual capabilities, covering 109 languages, which can contribute to more inclusive and accurate AI systems. It also features better image recognition and document understanding. The four model sizes offer flexibility and potentially increased accessibility for resource-constrained environments.
Models: https://github.com/google-research/big_vision/blob/main/big_vision/configs/proj/image_text/README_siglip2.md
Paper: SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features
https://arxiv.org/pdf/2502.14786
HuggingFace Blog and Demo: https://huggingface.co/blog/siglip2
Credits: "SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features" by Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Alabdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, Olivier Hénaff, Jeremiah Harmsen, Andreas Steiner, and Xiaohua Zhai (2025).