Absolutely stunning images of Gabon and Tchad from the European Space Agency’s (ESA) Biomass satellite.
The first image shows the Ivindo River in Gabon, stretching from the DRC border all the way to Makoukou in the Ogooué-Ivindo province. This region is known for its dense forests. Typically, when we look at forests from above, all we see are the treetops. However, Biomass uses a special kind of radar, called P-band radar, which has the ability to penetrate through the forest canopy to reveal the terrain below. This means it can measure all the woody material—the trunks, branches, and stems—offering a much more complete picture than ever before.
The second image features the Tibesti Mountains in northern Chad, and it looks like something straight out of space. Here, the radar demonstrates its ability to see up to five meters beneath dry sand. This opens up fascinating possibilities for mapping and studying hidden features in deserts, such as ancient riverbeds and lakes that have long been buried. Such insights are incredibly valuable for understanding Earth’s past climates and even for locating vital water sources in arid regions.
It’s an exciting time as our ability to collect information about Earth continues to advance, especially with progress in remote sensing and Artificial Intelligence (AI). The rise of geospatial AI, in particular, is opening up fascinating new avenues for understanding our planet and opening new fields of research.
If you’re a student considering a career in understanding Earth through technology, leveraging AI. In my opinion, this field presents some interesting opportunities. You can explore more about the amazing Biomass mission on the official ESA website:
For those in genomic research: Google DeepMind has released AlphaGenome, an AI model for predicting DNA sequences. The API is free for non-commercial research use.
Feel free to share this with anyone in the field who might be interested.
(Note: This post reflects my personal opinions and may not reflect those of my employer)
Example of the HeAR encoder that generates a machine learning representation (known as “embeddings”)
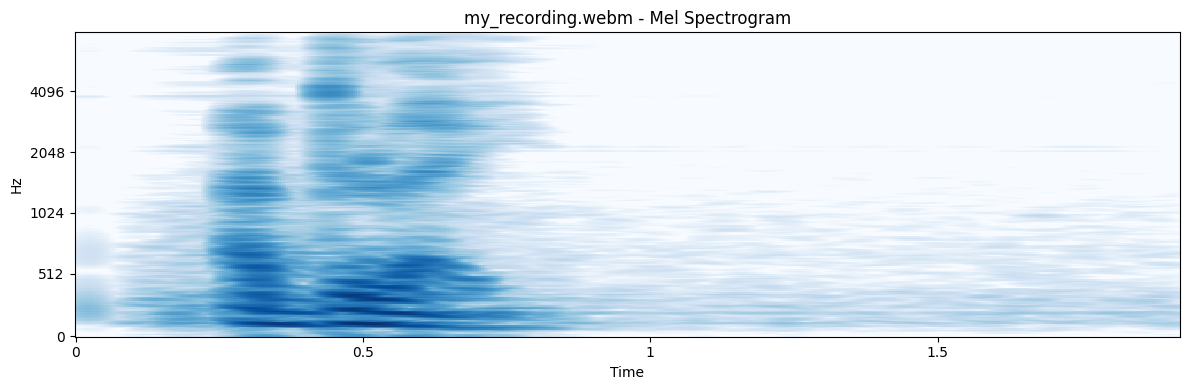
This image is a spectrogram representing my name, “Abdoulaye,” generated from my voice audio by HeAR (Health Acoustic Representations). HeAR is one of the recently released Health AI foundation models by Google. I’ve been captivated by these foundation models lately, spending time digging into them, playing with the demos and notebooks, reading ML papers about the models, and also learning more about embeddings in general and their usefulness in low-resource environments. All of this started after playing with a couple of the notebooks.
Embeddings are numerical representations of data. AI models learn to create these compact summaries (vectors) from various inputs like images, sounds, or text, capturing essential features. These information-rich numerical representations are useful because they can serve as a foundation for developing new, specialized AI models, potentially reducing the amount of task-specific data and development time required. This efficiency is especially crucial in settings where large, labeled medical datasets may be scarce.
If you would like to read further into what Embeddings are, Vicki Boykis’ essay is such a great free resource; this essay is also ideal to learn or dive into machine learning. I know many of my previous colleagues from the telco and engineering world will love this: https://vickiboykis.com/what_are_embeddings/
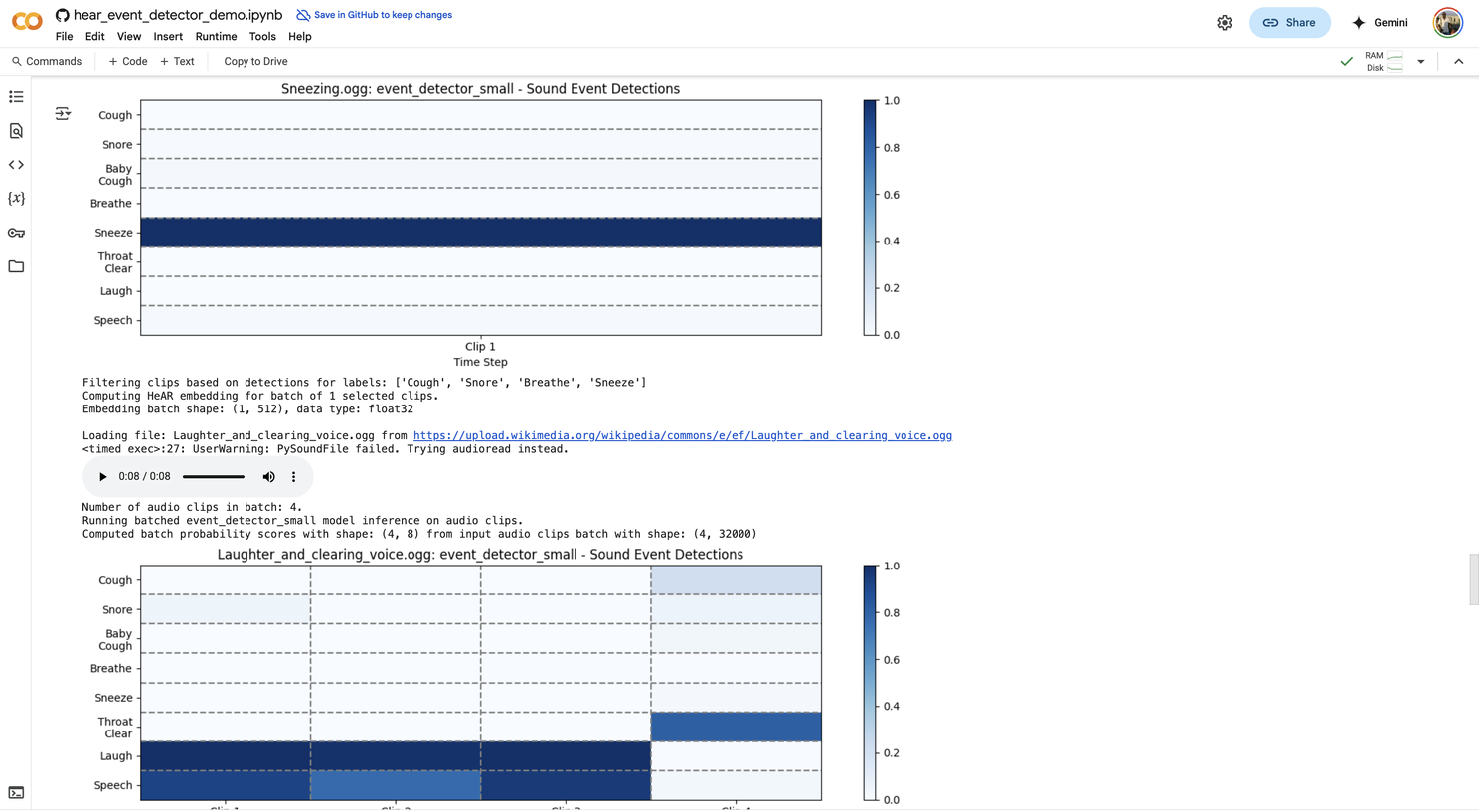
The HeAR model, which processed my voice audio, is trained on over 300 million audio clips (e.g., coughs, breathing, speech). Its application can extend to identifying acoustic biomarkers for conditions like TB or COVID-19. It utilizes a Vision Transformer (ViT) to analyze spectrograms. Below, you can see an example of sneezing being detected within an audio file, and later, throat clearing detected at the end.
This release also includes other open-weight foundation models, each designed to generate high-quality embeddings:
Derm Foundation (Skin Images) This model processes dermatology images to produce embeddings, aiming to make AI development for skin image analysis more efficient by reducing data and compute needs. It facilitates the development of tools for various tasks, such as classifying clinical conditions or assessing image quality.
Explore the Derm Foundation model site for more information and to download the model use this link.
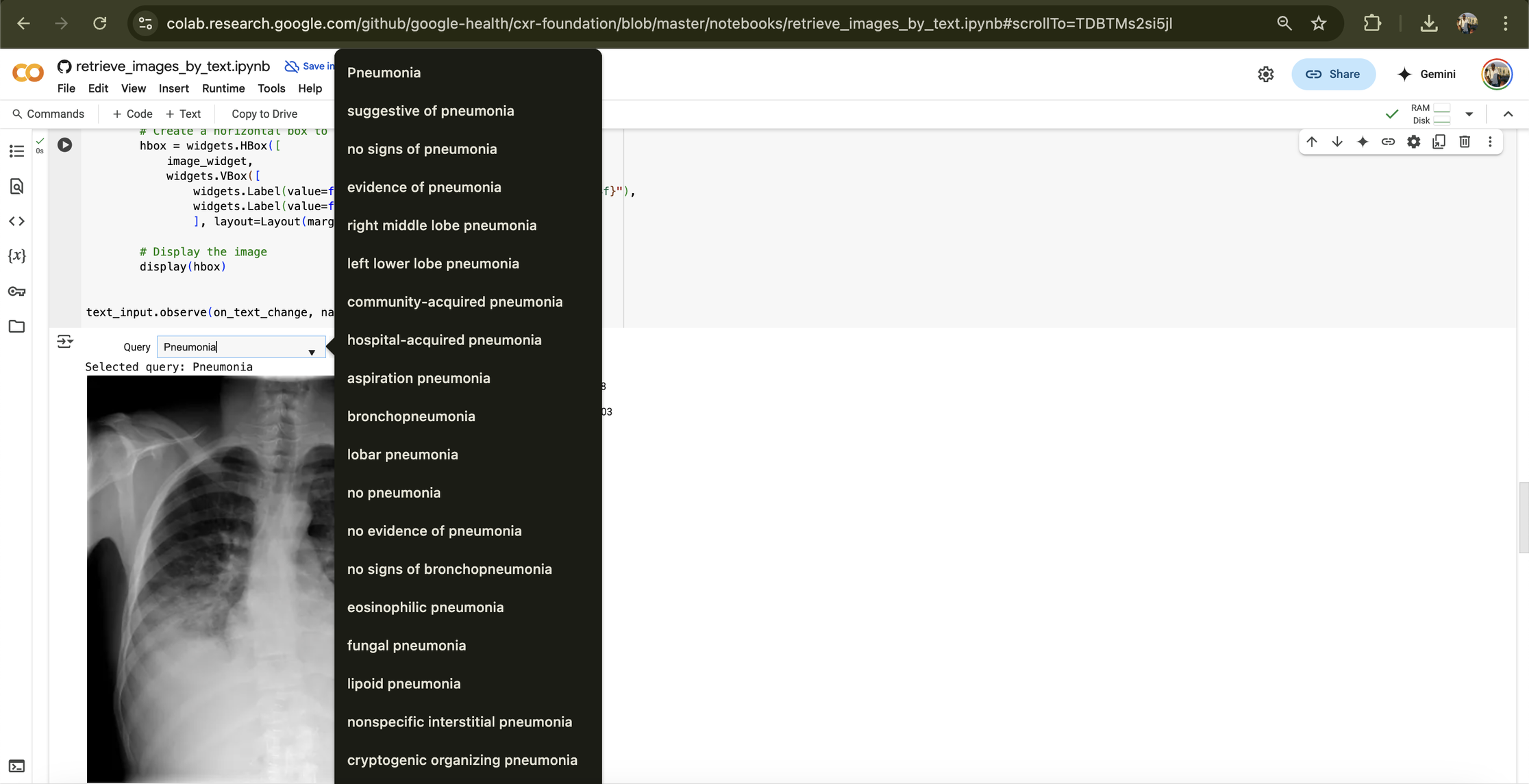
CXR Foundation (Chest X-rays) The CXR Foundation model produces embeddings from chest X-ray images, which can then be used to train models for various chest X-ray related tasks. The models were trained on very large X-ray datasets. What got my attention, some models within the collection, like ELIXR-C, use an approach inspired by CLIP (contrastive language-image pre-training) to link images with text descriptions, enabling powerful zero-shot classification. This means the model might classify an X-ray for a condition it wasn’t specifically trained on, simply by understanding a text description of that condition which i find fascinating. The embeddings generated can also be used to train models that can detect diseases like tuberculosis without a large amount of data; for instance, “models trained on the embeddings derived from just 45 tuberculosis-positive images were able to achieve diagnostic performance non-inferior to radiologists.” This data efficiency is particularly valuable in regions with limited access to large, labeled datasets. Read the paper for more details.
Path Foundation (Pathology Slides) Google’s Path Foundation model is trained on large-scale digital pathology datasets to produce embeddings from these complex microscopy images. Its primary purpose is to enable more efficient development of AI tools for pathology image analysis. This approach supports tasks like identifying tumor tissue or searching for similar image regions, using significantly less data and compute. See the impressive Path Foundation demos on HuggingFace.
Path foundation demos
Outlier Tissue Detector Demo
These models are provided as Open Weight with the goal of enabling developers and researchers to download and adapt them, fostering the creation of localized AI tools. In my opinion, this is particularly exciting for regions like Africa, where such tools could help address unique health challenges and bridge gaps in access to specialist diagnostic capabilities.
For those interested in the architectural and training methodologies, here are some of the pivotal papers and concepts relevant to these foundation models:
Vision Transformer (ViT): Applied in HeAR and Path Foundation. (An Image is Worth 16×16 Words: https://arxiv.org/abs/2010.11929)
Masked Autoencoders (MAE): A self-supervised learning technique used for HeAR. (Masked Autoencoders Are Scalable Vision Learners: https://arxiv.org/abs/2111.06377)
EfficientNet: The family of architectures related to the backbone for CXR Foundation models. (EfficientNet: https://arxiv.org/pdf/1905.11946)
Google DeepMind has released TxGemma, a set of open-weight AI models designed for therapeutic development. These models, based on the Gemma architecture, are trained to analyze and predict characteristics of therapeutic entities during drug discovery. 💊
The release includes ‘chat’ variants (9B and 27B) that can engage in dialogue and provide explanations for their predictions. Additionally, Agentic-Tx demonstrates the integration of TxGemma into an agentic system for multi-step research questions. 🤖
A fine-tuning notebook is available for custom task adaptation:
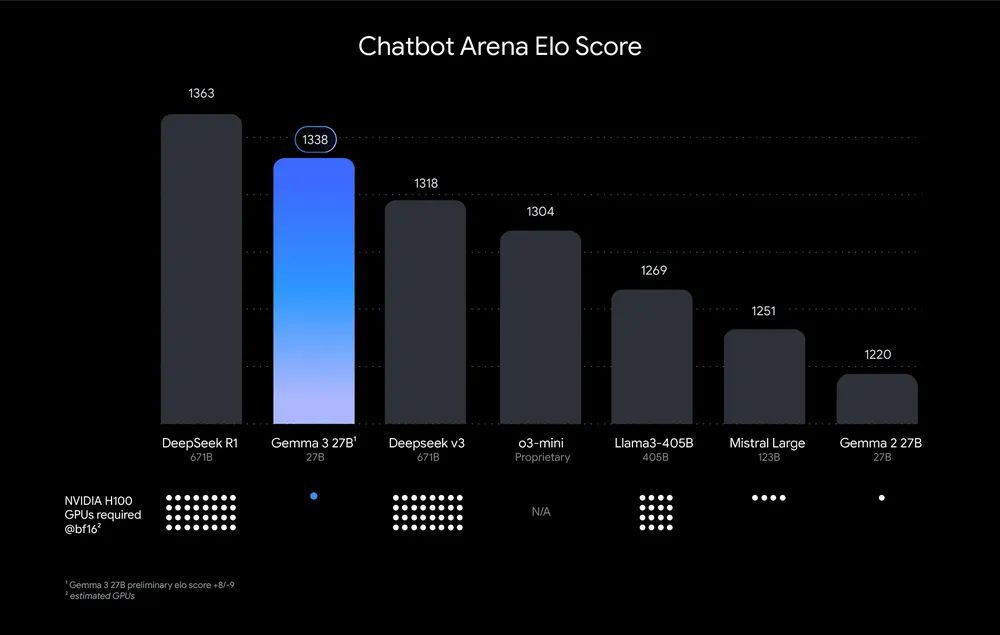
🚨 Gemma 3 is out! It’s a family of open AI models (1B-27B parameters) featuring a 128k token context window (can work with very long documents and conversations), multilingual support (35+ languages, trained on 140+), and single GPU/TPU compatibility. I’m excited about its potential to increase accessibility to advanced AI models, especially in resource-constrained settings, and the multimodal capabilities that can enable diverse applications.
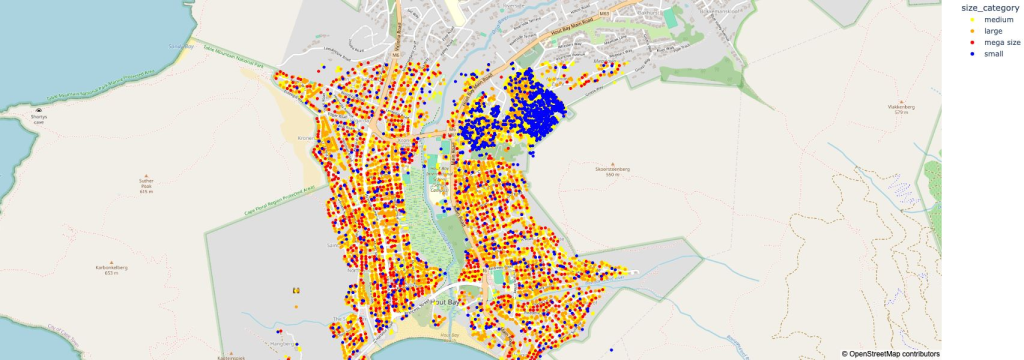
I tested the Gemini Datascience agent with the Hout Bay (Cape Town, South Africa) building data footprint, asking simple spatial questions, “show me small houses” and “identify crowded areas” “what about large houses with few neighbors”. The agent generates interesting visualizations and can select various algorithms, for example it picked k-Nearest Neighbors (k-NN) to detect houses with adjacent neighbors. I spent wayyy too much time on this, but I really liked the interactive aspect to make refinements iteratively by just making suggestions and asking for alternatives, kind of chatting with a Datascience expert :). I guess you would call this Conversational geospatial data analysis?
Google Colab has been updated with interesting new features. Julia is now supported natively, so no more need for workarounds! Plus, the Gemini Data Science agent is now more widely accessible. This agent lets you query data through simple prompts, like asking for trend visualizations or model comparisons. It aims to reduce the time spent on tasks like data loading and library imports. This can, for example, contribute to faster prototyping and more efficient data exploration.
I find this simply incredible. This new Taara chip is smaller than a fingernail, yet it can transmit data at 10 gigabits per second over a 1KM DISTANCE! 🤯🤯🤯
“In tests at the Moonshot Factory labs, our team has successfully transmitted data at 10 Gbps (gigabits per second) over distances of 1 kilometer outdoors using two Taara chips. We believe this is the first time silicon photonics chips have transmitted such high-capacity data outdoors at this distance. And this is just the beginning. We plan to extend both the chip’s range and capacity by creating an iteration with thousands of emitters.”
The previous version of Taara, the light bridge, steered light beams mechanically using mirrors and sensors. Now, they’ve shrunk it to the size of a coin, replacing much of the hardware with software. I’ve been a huge fan of this project for many years, and it’s exciting to see this ‘moonshot’ turning into reality. It can bring high-speed internet to underserved regions, change how data centers operate and so much more. Huge congrats to the Taara team!
How do you manage ML projects? 🤔 A question I hear often! Working in research over the years, I often got asked about the day-to-day of managing machine learning projects. That’s why I’m excited about Google’s new, FREE “Managing ML Projects” guide which I can now point to going forward. it’s only 90 minutes but a good start!
It can be useful for:
* Those entering the ML field 🚀: Providing a clear, structured approach. * Professionals seeking to refine their ML project management skills. * Individuals preparing for ML-related interviews: Offering practical insights and frameworks.
This guide covers:
* ML project lifecycle management. * Applying established project management principles to ML. * Navigating traditional and generative AI projects. * Effective stakeholder collaboration.
If you’re curious about ML project management, or want to level up your skills, take a look!