Don’t you agree this is pretty neat? 🐧 As a longtime Linux user (~20y), I got excited to see a native Debian environment land on Android 15. With regards to accessibility, a student can learn command line basics, debug while in transit, or even manage AI agents from their phone. I think having an isolated terminal in your pocket is a game changer. I tried both Google Gemini CLI and Claude Code on my device and it works quite well. No hacking or rooting required. For now, this is limited to Pixel devices, but I’m hoping we see this in more devices across the ecosystem. If you have a Pixel, here is how to unlock it: 1)Enable Developer Options. 2)Toggle on “Linux development environment.” 3) Install whatever you need (example) Open the terminal and run: sudo apt install npm npm install -g @google/gemini-cli
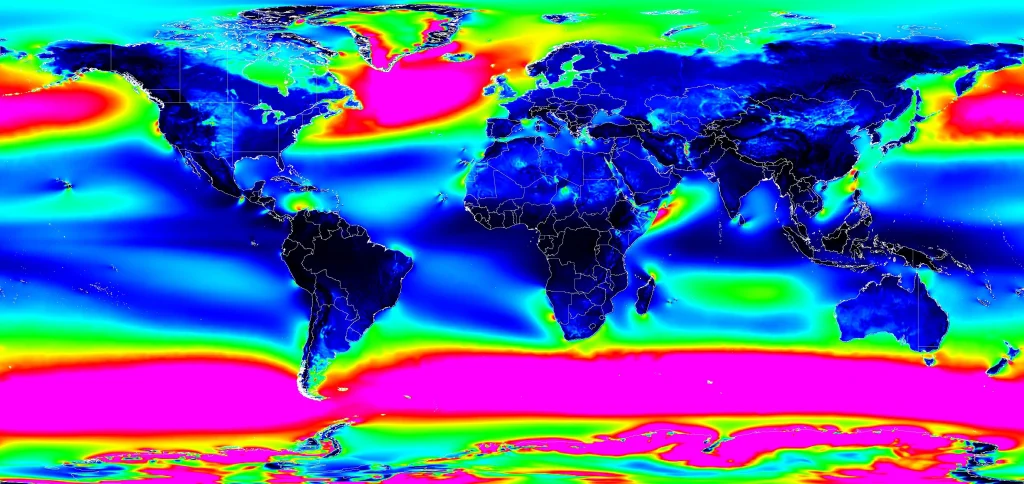
Until a few days ago, I hadn’t. I was exploring WeatherNext-2—an experimental AI weather forecasting model—when I stumbled upon something striking along the coast of East Africa. The visualization below shows global wind power potential at 100 meters (typical wind turbine height) forecasted by the model for 2025.
Global Wind Power Potential(100m) – 2025 (Experiment metric: Wind power density)
It looks like a jet engine shooting out of the Horn of Africa. A quick search confirmed this is the “Somali Jet,” a well-documented low-level atmospheric phenomenon.
But here’s what fascinated me: The AI model reproduced and forecast this jet stream without ever being explicitly programmed with the physics of fluid dynamics. It discovered this feature by learning from 40 years of historical weather data.
Going through this dataset made me feel we are going through a special moment—something noteworthy is happening in atmospheric science, and it’s worth understanding why.
The “AlphaGo” Moment for Weather forecasting
For decades, meteorology has relied on Numerical Weather Prediction (NWP). Scientists encode the fundamental laws of physics—how air pressure, temperature, humidity, and wind interact—into massive computer simulations. These models divide the atmosphere into millions of grid cells and calculate how conditions in each cell evolve over time. It’s amazing science and research, but it requires enormous computational resources. Running a global weather forecast on traditional systems is like playing chess by calculating every possible future position, it’s computationally expensive.
Learning from History
WeatherNext-2 represents a different approach, powered by a technique called FGN (Functional Generative Networks). Instead of being programmed with physics equations, the model learned atmospheric dynamics by “studying” patterns in 40 years of historical weather data.
Rather than teaching a computer the rules of chess and having it calculate moves, imagine showing it millions of chess games and letting it discover winning strategies on its own. That’s the shift happening in weather forecasting.
FGN outperforms the previous state-of-the-art ML model (GenCast) while providing an extra 24 hours of lead time for tracking tropical cyclones. That extra day can make a big difference to prepare.
Computational Efficiency: Despite being a larger model than GenCast, FGN generates a 15-day forecast in under 1 minute on a single TPU, 8 times faster than GenCast. This is because it requires only a single forward pass through the network, unlike diffusion models that need iterative refinement.
To put it simply, the model understands that the atmosphere is deeply interconnected—that the pressure in Dakar is linked to conditions in Nairobi. It learned from observing how weather patterns actually flow across our continent and around the world.
What Makes FGN Different
Traditional ML weather models predict a single “most likely” outcome. FGN generates ensembles—64 different plausible scenarios for how weather might evolve.
What is fascinating is that FGN learned to produce these realistic probability distributions while being trained only to minimize error at individual locations (what researchers call “marginal distributions”). It wasn’t explicitly taught about spatial correlations or how different weather variables relate to each other—it discovered these relationships on its own.
To put it simply, imagine a Council of Four Grandmasters that work together to map out all the possibilities of a chess game. FGN in production employs 4 expert models to provide 64 distinct potential futures (an ensemble). This allows us to see the full range of risks—all generated in under one minute on a single TPU.
The “Clever Trick” To prevent the “blurriness” common in generative AI, WeatherNext-2 employs a Graph Transformer that injects a shared noise vector to enforce physical consistency across the globe. Imagine a conductor’s baton used to lead a symphony: this architecture allows complex global patterns (joint structure) to emerge naturally, enabling the model to master the entire planet’s weather despite being trained solely on individual locations.
A side note: If I had to pick a word for 2025, it would be “ensemble”. Ensemble forecasts, ensemble of models, mixture of experts— feels like a pattern. Diverse, specialized components working together beat singular “optimal” solutions. Four weather models trained independently outperform one perfect model.
Key Innovation: FGN generates probability distributions for weather forecasts by modeling both epistemic uncertainty (what we don’t know about the model) and aleatoric uncertainty (the inherent randomness in weather) through learned variations in the neural network’s parameters.
For those who want to hear about the research and the evolution of these models, I highly recommend this video by my colleague and one of the lead authors Ferran Alet Puig , as well as the original paper.
The WeatherNext-2 dataset acts as a massive archive of forecasts, generating new 15-day predictions every 6 hours. It’s accessible through Google Earth Engine, BigQuery, and as raw data files (you need to apply to get access).
The data includes:
Surface Variables: Temperature, precipitation, wind speed and direction at 10m and 100m above ground
Atmospheric Variables: Humidity, geopotential (related to altitude and pressure), and wind vectors at 13 different pressure levels throughout the atmosphere
Ensemble Predictions: 64 different scenarios for each variable, allowing us to calculate probabilities and confidence intervals
Data info: The model is trained on 40 years of historical weather data from ECMWF (1979-2022), using ERA5 reanalysis for pre-training and more recent operational data for fine-tuning.
Important note: Visualizations in this post are AI predictions, not observations of reality. I’m someone in research exploring geospatial data, not a climate scientist. Always refer to official meteorological agencies for actionable weather information.
Experiments: Exploring What the Model Reveals
1. Wind Energy Potential: From the Somali Jet to Global Patterns
The Somali Jet discovery got me curious: Where else might significant wind energy potential exist that we haven’t fully recognized?
Since the dataset includes wind speeds at 100 meters—the typical hub height for modern wind turbines—I combined this with the Google Open Buildings dataset to create theoretical infrastructure analyses. I simulated how a single industrial wind turbine could potentially serve households within a 5-kilometer radius.
The results surprised me.
Beyond well-known locations like the UK and South Africa, the model highlighted promising potential in:
The Mauritanian coast
Central Sahara in Chad
The coast of Somalia
Barranquilla, Colombia
Traditional wind resource assessment requires deploying expensive LIDAR equipment for up to a year at each potential site. While AI models can’t replace ground-truthing, they could dramatically reduce the search space for where to invest in detailed surveys—particularly valuable for developing regions with limited resources.
Note: These are exploratory visualizations based on forecasted wind patterns, not engineering assessments. Actual wind farm development requires detailed on-site measurements, environmental impact studies, and grid integration analysis.
2. Atmospheric Rivers: Visualizing Invisible Water Highways
Atmospheric rivers are narrow corridors of concentrated water vapor in the atmosphere—essentially rivers in the sky. When they make landfall, they can deliver enormous amounts of precipitation in a short time, causing both beneficial water supply and devastating floods.
Because FGN’s forecasts include both wind vectors and moisture data, I attempted to visualize these phenomena. The results were mesmerizing—you can see moisture being transported across entire ocean basins in streams.
Understanding and predicting atmospheric rivers is critical for water resource management and flood preparedness.
3. Storm Tracking: Melissa and Typhoon Fung-Wong
To evaluate the model’s forecasting performance, I compared its predictions against actual tropical cyclone tracks from 2025.
The animations below show Storm Melissa and Typhoon Fung-Wong, with the AI’s forecast tracks (generated days in advance) plotted against the actual paths recorded by the International Best Track Archive for Climate Stewardship (IBTrACS).
Important note: While FGN shows measurable improvements over previous models—specifically that 24-hour advantage in cyclone tracking lead time—all forecasting systems become less accurate as lead time increases. Weather is chaotic, and even the best models have uncertainty limits.
I also used the dataset to visualize significant weather events from 2025.
European Heatwaves: I was actually in London during the summer heatwave, visiting from Ghana. Seeing people walking around with mini-fans was surreal—and the model had captured this moment in its forecasts.
African Heat Patterns: I was also keen to vizualize the model’s forecasts of high-temperature events (above 35°C) across Africa to see seasonal patterns and localized extreme heat events. Understanding the predictability of these conditions could help with things such as agricultural planning.
Wind and Rain Patterns: This final visualization shows the interplay of winds and rainfall that shaped weather across the globe in 2025. The blue-to-orange gradient represents wind intensity, while the neon glow highlights precipitation.
My take away from this exploration
We are entering an era where high-resolution, probabilistic forecasting will not necessarily require supercomputing resources. This changes the economic calculus for regions like East Africa—whether that means better storm preparedness or identifying untapped wind potential in the Sahel.
For centuries, we have modeled the world by understanding the rules first, then simulating them. This model does the inverse: it observes the output (the weather) and infers the dynamics, effectively “rediscovering” features like the Somali Jet without ever seeing a physics equation.
If an AI can empirically derive the laws of fluid dynamics without the theoretical equations, what does this mean for modeling other complex systems?
There are obvious limits—these models can’t explain why something works in human-interpretable terms. But could this data-driven approach complement theoretical physics in powerful ways?
It is genuinely inspiring to witness the profound shift my colleagues are driving in how we understand our planet.
A Personal Note: The Changing Nature of Technical Work
There’s another layer to this story worth sharing.
Back at PyCon Africa 2022, I gave a talk about AI-assisted coding. I knew it was coming, but I had no idea how quickly it would transform my personal workflow.
A year ago, producing the visualizations for this post—writing the Earth Engine logic & code, debugging the vector mathematics, and fine-tuning the palettes—would have taken me weeks if not more. For this post, I iterated with Gemini to generate 80% of the code.
To be clear, it wasn’t magic. I still had to intervene quite a few times e.g fixing the code or catching “hallucinations”. But what used to be a weeks-long “project” became a fun afternoon of debugging and curation.
As we look toward 2026, I believe you will see this across many fields. Software engineers have always carried a toolkit, but that toolkit just got an upgrade. From agent frameworks to AI coding assistants, the friction now lies in mastering these new instruments and the environment.
The Paradox of Easier Code Generation
Even with AI generating code much faster than I could write it manually, software engineering principles have never been more important. When you can generate hundreds of lines in an afternoon instead of weeks, the discipline to structure, test, document, and maintain that code becomes critical. The code comes faster, but the thinking can’t be rushed. You still need to know what to build, how it should be architected, why certain approaches are better than others (e.g cost, performance,etc..) and have a plan to maintain it. It feels like we’re moving from a constraint on capability to a constraint on curiosity and judgment. The bottleneck is no longer “can I build this?” but “which solution should I select?”.
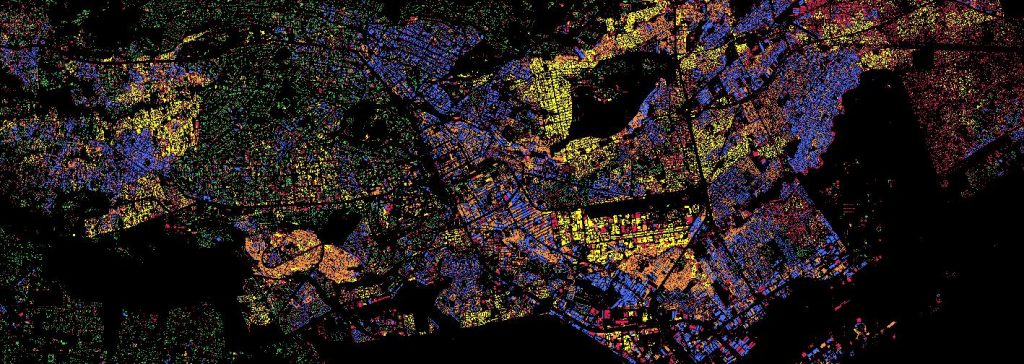
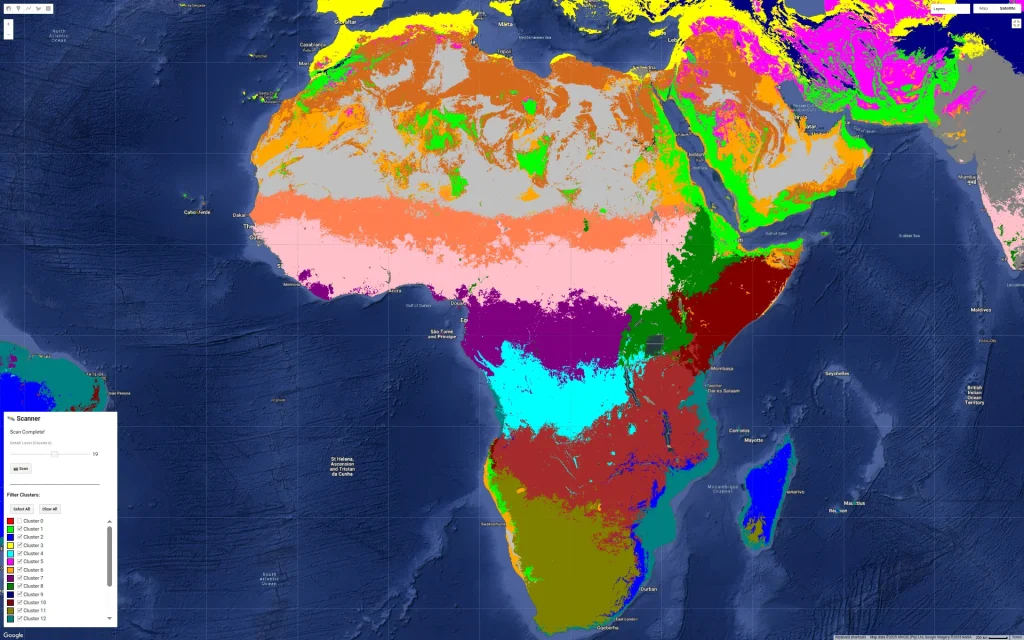
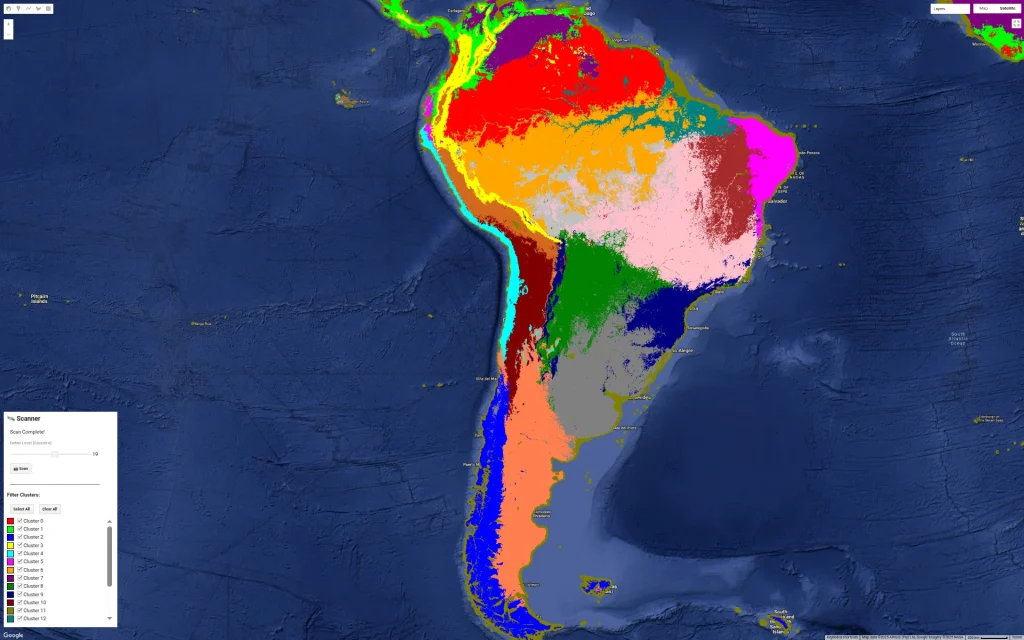
I’ve been experimenting with a fun way to visualize urban density by mixing the Google Open Buildings dataset with AlphaEarth embeddings. I’m using unsupervised clustering on top of AlphaEarth’s embeddings. Instead of coloring pixels for each area, I’ve assigned the cluster color to the building polygons themselves. The result is an interesting “fingerprint” of these cities. The clustering logic is still a bit of a mystery tobe honest, it could be picking up on building materials, street orientation, or height ect.. In some case it is just picking water bodies or green spaces. Anyway it reveals patterns that would be hard to see from a satellite image. One takeaway I have from looking at many African cities so far is the lack of green spaces which is not a secret but very visible… I am also sharing screenshots of clustering on continents and major cities but without the buildings.
// Google Open Buildings v3 view with AlphaEarth embeddings
// Experimental script - CCBY4
// --- 1. DYNAMIC GEOMETRY ---
// How to use it: Choose your current view on the map and click run
// --- 1. CAPTURE THE VIEW ---
var bounds = Map.getBounds(true);
var cityROI = ee.Geometry(bounds);
// --- 2. DATA LOADING (LOCKED TO 2023) ---
var alphaEarth = ee.ImageCollection("GOOGLE/SATELLITE_EMBEDDING/V1/ANNUAL")
.filterBounds(cityROI)
.filter(ee.Filter.date('2023-01-01', '2023-12-31'))
.first()
.clip(cityROI);
var buildings25D = ee.ImageCollection('GOOGLE/Research/open-buildings-temporal/v1')
.filterBounds(cityROI)
.filter(ee.Filter.eq('inference_time_epoch_s', 1688108400))
.mosaic()
.clip(cityROI);
var buildingPresence = buildings25D.select('building_presence');
// --- 3. SURGICAL TRAINING (BUILDINGS ONLY) ---
// We mask AlphaEarth BEFORE sampling so the trainer ONLY sees building signatures.
var buildingMask = buildingPresence.gt(0.2);
var alphaOnlyBuildings = alphaEarth.updateMask(buildingMask);
var training = alphaOnlyBuildings.sample({
region: cityROI,
scale: 10, // Native resolution for high precision
numPixels: 5000,
tileScale: 16,
dropNulls: true // CRITICAL: This ignores non-building pixels
});
// Train Clusterer on the BUILDING signatures only
var clusterer = ee.Clusterer.wekaKMeans(6).train(training);
// Apply that "Building-Logic" to the whole city
var allClusters = alphaEarth.cluster(clusterer);
// Final visualization mask
var finalClusters = allClusters.updateMask(buildingMask);
// --- 4. VISUALIZATION ---
var clusterPalette = ['#e6194b', '#3cb44b', '#ffe119', '#4363d8', '#f58231', '#911eb4'];
var blackBackground = ee.Image(0).visualize({palette: ['#000000']});
Map.addLayer(blackBackground, {}, '1. Black Background');
Map.addLayer(finalClusters, {min: 0, max: 5, palette: clusterPalette}, '2. Surgical Building Clusters');
// --- 5. EXPORT ---
Export.image.toDrive({
image: finalClusters.visualize({min: 0, max: 5, palette: clusterPalette}),
description: 'ROI_2023_Building_Clusters',
scale: 10,
region: cityROI,
fileFormat: 'GeoTIFF',
maxPixels: 1e13
});
You can now interact with a database in English—the real NoSQL 🙂
As someone who has done a lot of database administration and written a lot of SQL queries in the past, this is the stuff of dreams!
So this week when Google announced Gemini CLI extensions, I was particularly interested in the new database extensions which allow you to interact with MySQL and PostgreSQL using natural language. I also tried it in French, and it works, including giving the query feedback also in French.
Here’s a guide to get started if you want to try yourself:
Prerequisites
You need to have a MySQL server installed and running.
You will need the wget and unzip command-line utilities.
Step 1: Download the Sakila Sample Database
First, you need to download and unpack the sample database files from MySQL. These commands will download the zip archive and extract the SQL files into a new directory called sakila-db.
Bash
# Download the official Sakila database archive
wget https://downloads.mysql.com/docs/sakila-db.zip
# Unzip the archive
unzip sakila-db.zip
After running these commands, you should have the sakila-schema.sql and sakila-data.sql files inside the sakila-db directory.
Step 2: Install the Gemini CLI
Next, install the Gemini Command Line Interface (CLI). Open your terminal and run the following command. This will download and run the installation script.
Follow the on-screen instructions to complete the installation.
Step 3: Install the MySQL Extension
The Gemini CLI uses extensions to connect to different tools and services. To connect to your database, you’ll need to install the MySQL extension.
Bash
gemini extension install mysql
You can check the installed extensions and available command by running this command in gemini cli:
/mcp list
Step 4: Set up the Sakila Sample Database
Now, we’ll load the Sakila database into your MySQL server. This database, which models a DVD rental store, will provide a good dataset for testing queries.
Create the database:Bashmysql -u YOUR_USERNAME -p -e "CREATE DATABASE sakila;" (Replace YOUR_USERNAME with your MySQL username. You will be prompted for your password.)
Import the schema (the table structures):Bashmysql -u YOUR_USERNAME -p sakila < sakila-db/sakila-schema.sql
Import the data:Bashmysql -u YOUR_USERNAME -p sakila < sakila-db/sakila-data.sql
Step 5: Configure the Database Connection
The Gemini CLI needs to know how to connect to your database. It uses environment variables for this. You’ll need to set these in your terminal.
Important: For the extension to work, you must set these variables before you start the Gemini CLI.
(Replace YOUR_USERNAME and YOUR_PASSWORD with your MySQL credentials).
Step 6: Start Gemini CLI and Query in English
Now you’re ready. Start the Gemini CLI:
Bash
gemini
Once it’s running, you can start asking it questions about the database in plain English. The MySQL extension will translate your questions into SQL queries and show you the results.
Example Prompts:
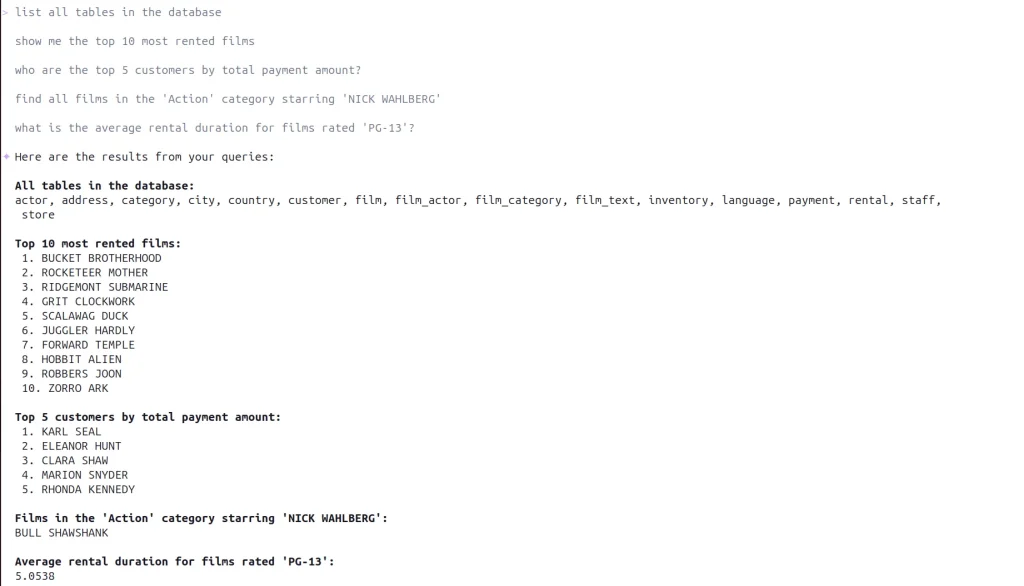
Try asking some of these questions. You don’t need to know any SQL!
list all tables in the database
show me the top 10 most rented films
who are the top 5 customers by total payment amount?
find all films in the 'Action' category starring 'NICK WAHLBERG'
what is the average rental duration for films rated 'PG-13'?
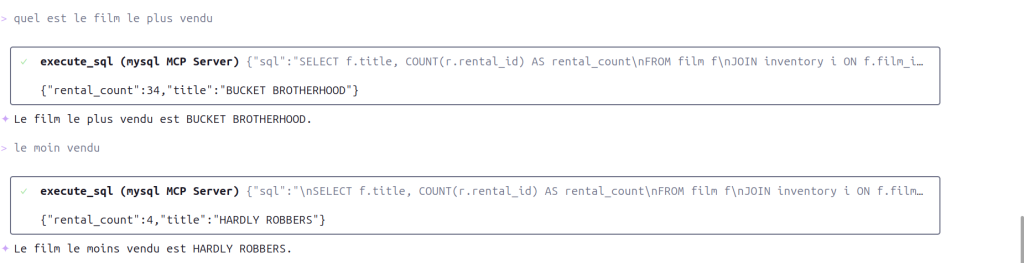
You can now explore the database just by having a conversation.
Fun Sunday exercise, how much useful information I can squeeze in a tiny AI model. My goal was to take a general-purpose language model and turn it into an expert on a topic vital such as agriculture.
Here are my steps:
1. The Foundation: Google’s Gemma 270M
I started with this small but powerful but compact base model, gemma-3-270m-it. At just 550 MB, it’s a brilliant piece of engineering that can run on consumer-grade hardware.I am using my laptop.
2. The Technique: Parameter-Efficient Fine-Tuning (PEFT) with LoRA
Instead of retraining the entire model (which is slow and resource-intensive), I used a technique called LoRA. Think of it like adding a small, highly specialized “expert module” to the model’s existing brain. The original model’s knowledge remains, but we efficiently “teach” it a new skill, in this case agricultural information.
3. The Curriculum: The Agriculture Q&A Dataset
I used the KisanVaani/agriculture-qa dataset to teach the model the nuances of farming, crops, pests, and soil.
After a 15m training session, the new “expert module” I created was only 45 MB! That’s right. For just 45 MB, I layered deep agricultural knowledge onto a powerful base model. This process has created a specialized AI assistant that is more accurate and relevant for agricultural queries than the original.
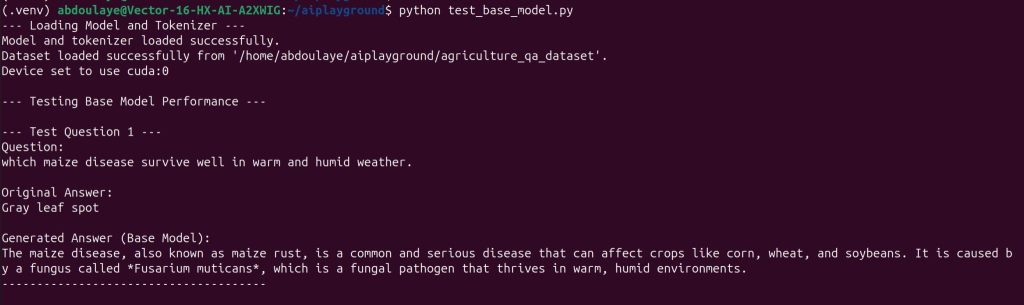
Model output:
— Loading Model and Tokenizer —
Model and tokenizer loaded successfully.
Dataset loaded successfully from ‘/home/abdoulaye/aiplayground/agriculture_qa_dataset’.
Device set to use cuda:0
— Testing Base Model Performance —
— Test Question 1 —
Question:
which maize disease survive well in warm and humid weather.
Original Answer:
Gray leaf spot
Generated Answer (Base Model):
The maize disease, also known as the maize blight, is a fungal disease that can affect maize plants, particularly in areas with high humidity and high temperatures. It’s a common problem in many parts of the world, and it can be difficult to control.
————————————–
— Test Question 2 —
Question:
how can overuse of pesticides destroy soil nutrients?
Original Answer:
Pesticides can kill beneficial soil microorganisms and reduce soil biodiversity, which can lead to nutrient depletion and reduced soil fertility.
Generated Answer (Base Model):
Overuse of pesticides can be a serious threat to soil nutrients, which are essential for plant growth, soil health, and overall ecosystem function. Here are some ways pesticides can negatively impact soil nutrients:
* **Reduced nutrient availability:** Pesticides can disrupt the natural nutrient cycle, leading to nutrient deficiencies and reduced plant growth.
* **Soil degradation:** Pesticides can cause soil erosion, compaction, and altered soil structure, weakening the soil’s ability to retain nutrients.
* **Reduced plant health:** Pesticides can suppress plant growth, leading to stunted development, reduced yields, and increased susceptibility to disease.
* **Soil contamination:** Pesticides can contaminate soil with harmful chemicals, which can harm soil microorganisms, leading to soil degradation and reduced nutrient availability.
* **Impact on plant physiology:** Pesticides can affect plant physiology, including nutrient uptake, metabolism, and stress tolerance.
* **Altered soil pH:** Pesticides can alter soil pH, which can affect the availability of essential nutrients.
This quick experiment shows small AI models can provide practical solutions. By using efficient models like Gemma and smart techniques like LoRA, we can build tools that understand various local contexts.
The power to build specialized AI is here, and I’m excited to see what people will build in my region.
For those interested in the technical details, I used the Hugging Face Transformers library to handle the model and the PEFT library’s implementation of LoRA for efficient training. You can learn more about them at the links below:
* For the Hugging Face `transformers` library: This is the main documentation, the central hub for everything related to the library.
* For LoRA and PEFT (Parameter-Efficient Fine-Tuning): This link goes directly to the Hugging Face documentation for the peft library, which is what you used to implement LoRA.
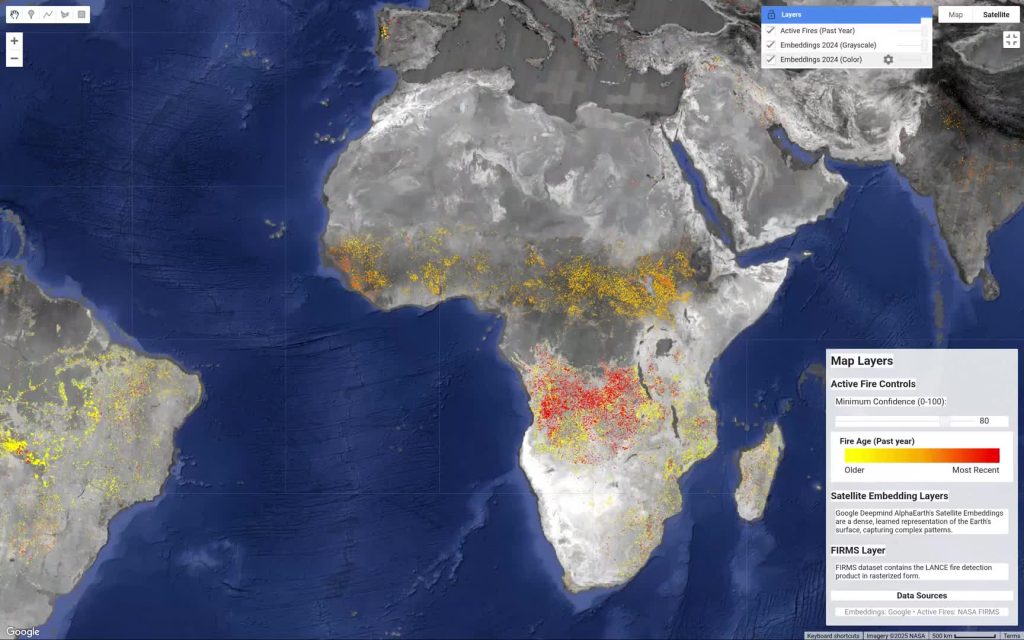
I started this exercise wondering how Google DeepMind’s AlphaEarth embeddings dataset would compare to historical fire data. It turned out to be a really interesting experience. I learned there are a lot of fires in central Africa—especially Southern DRC, Angola, and Zambia—far more than I expected. Apparently, some fires are set on purpose as part of an agricultural practice. Still, it’s worrying to see so many fires, especially when you think about the ones recently in the news across North America and Southern Europe. Funny enough, I hadn’t even noticed the pattern until my 9-year-old son pointed out the region to me while we were checking the map. I find the AlphaEarth dataset fascinating, as you can see a clear correlation between the type of landscape and where fires happen. I used Gemini to generate the boilerplate JavaScript for Google Earth Engine, and I had this visualization running in a few minutes. Gemini is quite good at generating JavaScript for Google Earth Engine.
Video caption: The colorful background is an AI’s unique “fingerprint” of our planet, where landscapes with similar characteristics get similar colors. Overlaid on top, the yellow/orange/red dots are real fire hotspots detected by NASA satellites over the last year with a confidence level set at 80%.
Video caption: The colorful background is an AI’s unique “fingerprint” of our planet, where landscapes with similar characteristics get similar colors. Overlaid on top, the yellow/orange/red dots are real fire hotspots detected by NASA satellites over the last year with a confidence level set at 80%.
Google Colab has been updated with interesting new features. Julia is now supported natively, so no more need for workarounds! Plus, the Gemini Data Science agent is now more widely accessible. This agent lets you query data through simple prompts, like asking for trend visualizations or model comparisons. It aims to reduce the time spent on tasks like data loading and library imports. This can, for example, contribute to faster prototyping and more efficient data exploration.
How do you manage ML projects? 🤔 A question I hear often! Working in research over the years, I often got asked about the day-to-day of managing machine learning projects. That’s why I’m excited about Google’s new, FREE “Managing ML Projects” guide which I can now point to going forward. it’s only 90 minutes but a good start!
It can be useful for:
* Those entering the ML field 🚀: Providing a clear, structured approach. * Professionals seeking to refine their ML project management skills. * Individuals preparing for ML-related interviews: Offering practical insights and frameworks.
This guide covers:
* ML project lifecycle management. * Applying established project management principles to ML. * Navigating traditional and generative AI projects. * Effective stakeholder collaboration.
If you’re curious about ML project management, or want to level up your skills, take a look!
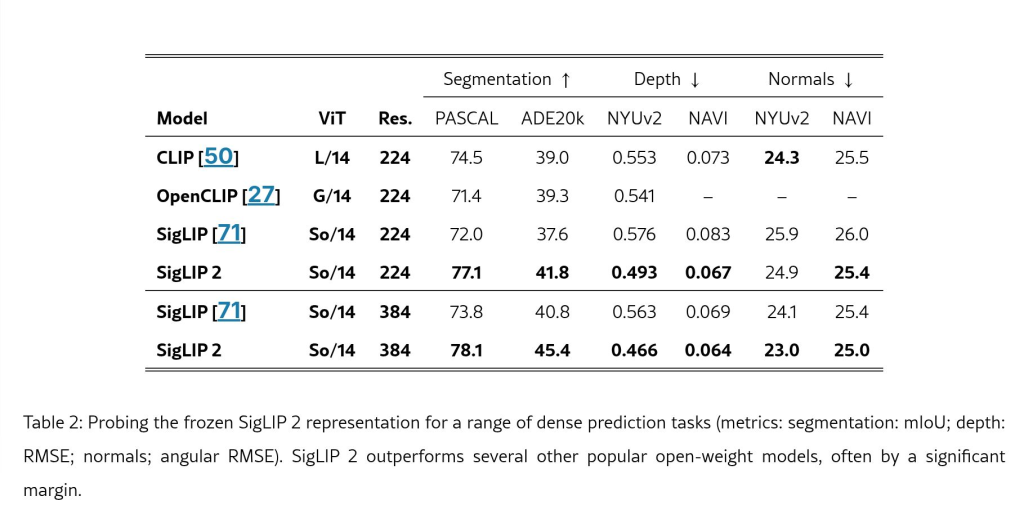
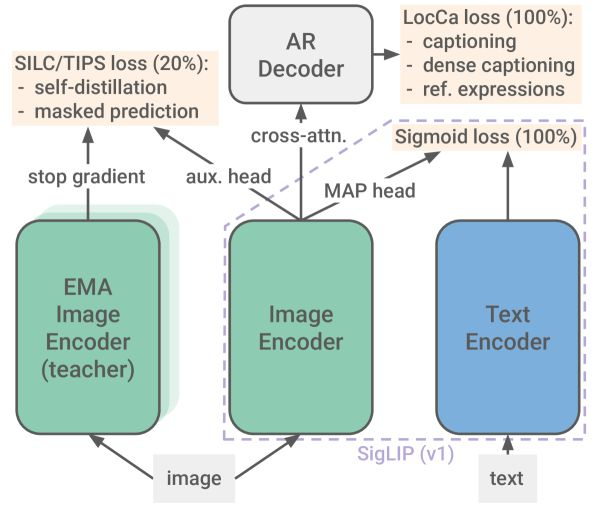
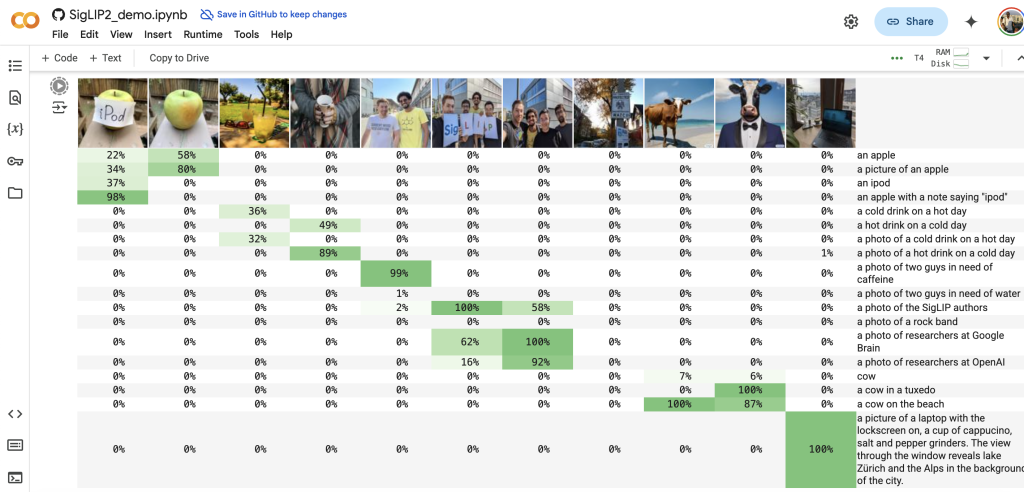
Google DeepMind has released SigLIP 2, a family of Open-weight (Apache V2) vision-language encoders trained on data covering 109 languages, including Swahili. The released models are available in four sizes: ViT-B (86M), L (303M), So400m (400M), and g (1B).
Why is this important?
This release offers improved multilingual capabilities, covering 109 languages, which can contribute to more inclusive and accurate AI systems. It also features better image recognition and document understanding. The four model sizes offer flexibility and potentially increased accessibility for resource-constrained environments.
Credits: "SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features" by Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Alabdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, Olivier Hénaff, Jeremiah Harmsen, Andreas Steiner, and Xiaohua Zhai (2025).
🎉 My colleagues and members of the language community have released SMOL, a new open-source dataset (CC-BY-4) designed for machine translation research. SMOL includes professionally translated parallel text for over 115 low-resource languages, with a significant representation of over 50 African languages. This dataset is intended to provide a valuable resource for researchers working on machine translation for under-represented languages.
Kindly check the paper for more details including limitations of this dataset.
Afar Acoli Afrikaans Alur Amharic Bambara Baoulé Bemba (Zambia) Berber Chiga Dinka Dombe Dyula Efik Ewe Fon Fulfulde Ga Hausa Igbo Kikuyu Kongo Kanuri Krio Kituba (DRC) Lingala Luo Kiluba (Luba-Katanga) Malagasy Mossi North Ndebele Ndau Nigerian Pidgin Oromo Rundi Kinyarwanda Sepedi Shona Somali South Ndebele Susu Swati Swahili Tamazight Tigrinya Tiv Tsonga Tumbuka Tswana Twi Venda Wolof Xhosa Yoruba Zulu
Credits:
Isaac Caswell and Elizabeth Nielsen and Jiaming Luo and Colin Cherry and Geza Kovacs and Hadar Shemtov and Partha Talukdar and Dinesh Tewari and Baba Mamadi Diane and Koulako Moussa Doumbouya and Djibrila Diane and Solo Farabado Cissé. SMOL: Professionally translated parallel data for 115 under-represented languages.