Active volcanoes are some of the most dynamic features on Earth, yet monitoring them on the ground is expensive and dangerous. I’m not very familiar with professional satellite observation platforms, but I imagine they are resource-intensive and require manual checking.
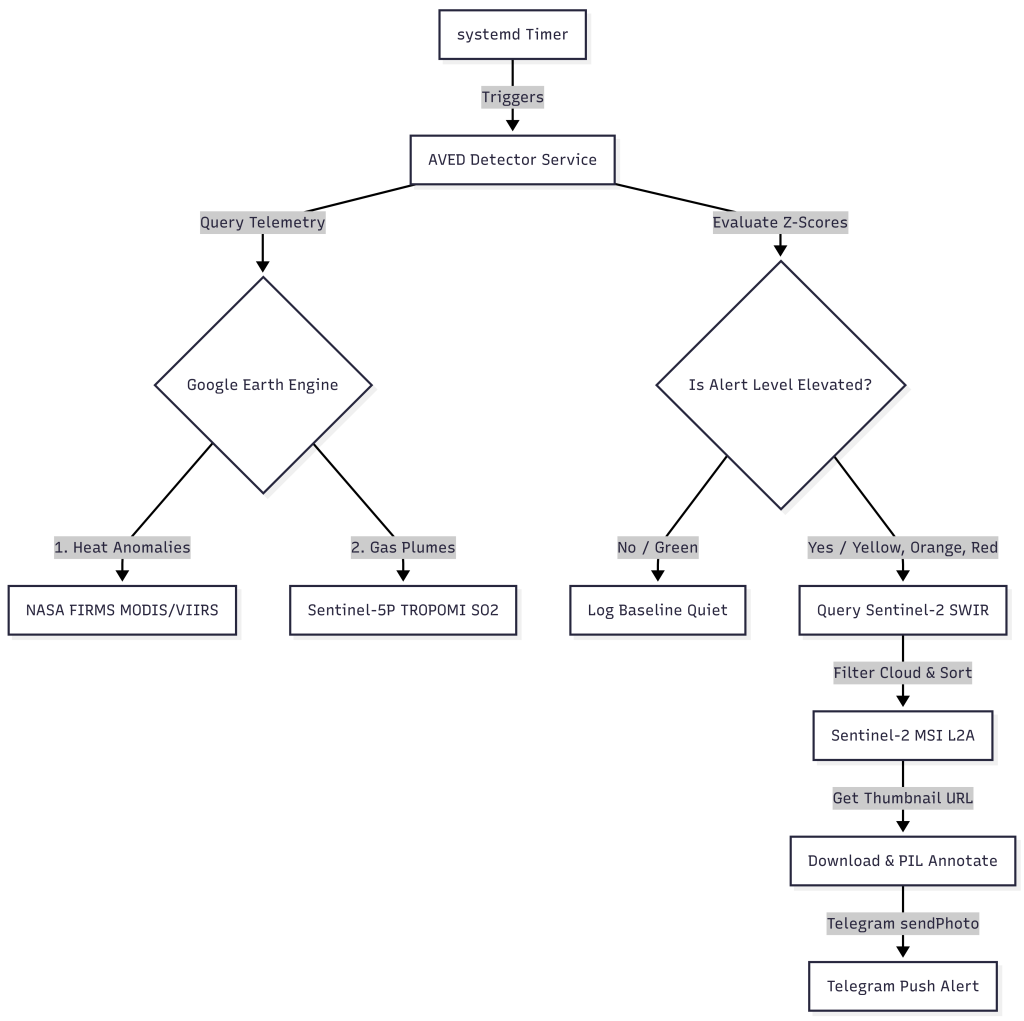
So I asked myself: could I build a cheap, agentic detection system that runs on a cloud micro-instance and give it a fancy name like AVED (Autonomous Volcanic Eruption Detector)? It is a lightweight, event-driven pipeline that integrates Google Earth Engine (GEE), Python systemd services (acting like a crontab), and Telegram to alert me within a few hours when a volcano shows signs of unrest.
Here is a look at how the system works under the hood and how it combines three distinct satellite instruments.
The Architecture: Multi-Sensor Fusion
Instead of querying heavy imagery continuously (which consumes massive processing quotas and storage), AVED operates on a two-stage, event-driven lifecycle.
Stage 1: The Near-Real-Time Trigger (FIRMS & Sentinel-5P)
The detector checks volcano coordinates periodically (via systemd timers) by querying GEE for two datasets:
NASA’s FIRMS (Thermal Hotspots): Uses MODIS and VIIRS satellite sensors. It detects thermal anomalies and updates multiple times a day with a 3 to 12-hour latency.
Copernicus Sentinel-5P (Atmospheric SO₂): Measures atmospheric Sulfur Dioxide (SO₂) columns daily with a 1 to 2-day latency.
We evaluate this telemetry using statistical Z-scores against a 30-day baseline. If the Z-score exceeds thresholds (indicating abnormal heating or gas emission), the pipeline transitions to Stage 2.
Only when an alert is flagged (Level YELLOW, ORANGE, or RED) does the agent execute the heavier imaging pipeline:
The Instrument: It queries Sentinel-2 (MSI) Level-2A surface reflectance data. Sentinel-2 has a 5-day revisit cycle.
Cloud Filtering & Sorting: It filters the last 30 days of data over the caldera, sorts them by CLOUDY_PIXEL_PERCENTAGE, and grabs the clearest image.
The Bands: We select bands B12 (Short-Wave Infrared 2), B8 (Near-Infrared), and B4 (Red). In this false-color configuration, vegetation shows up as vibrant green, volcanic rock as dark brown/black, and active hot spots (lava lakes or flows) glow in bright red/orange/yellow.
Auto-Annotating the Output
To make the alert actionable, the script downloads the GEE thumbnail and uses Pillow (PIL) to draw a semi-transparent dark banner at the bottom with crucial metadata:
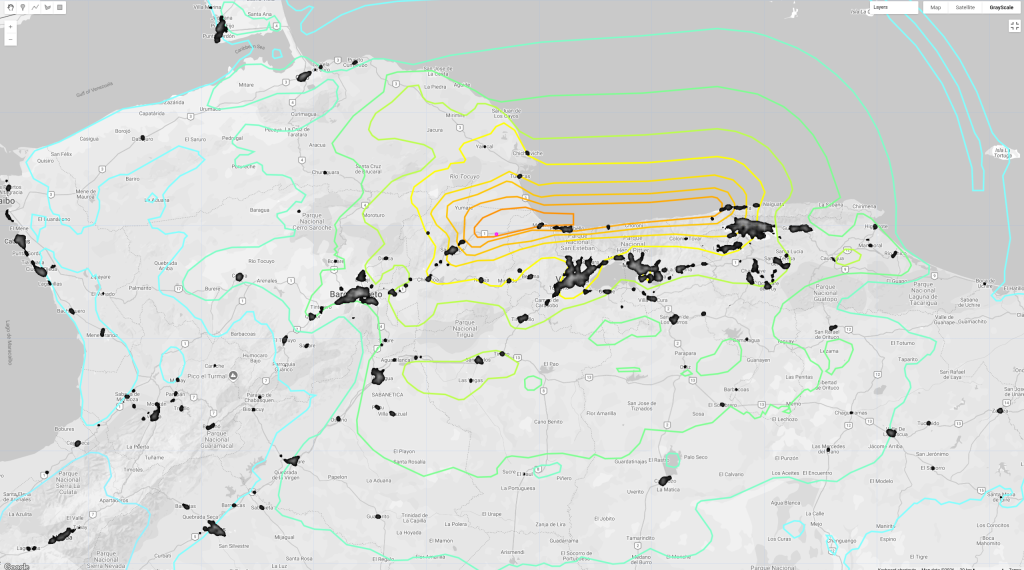
Below is the verified output generated during the active alert for Mt. Nyiragongo in the DRC:
Can you spot active lava lake glowing in red at the crater center? You should also see the gaseous sulfur plume drifting towards the southwest.
Production Verification
I deployed the system to my Cloud instance on Google Cloud. Shortly after activation, the pipeline flagged an elevated YELLOW alert for Mt. Nyiragongo in the Democratic Republic of the Congo.
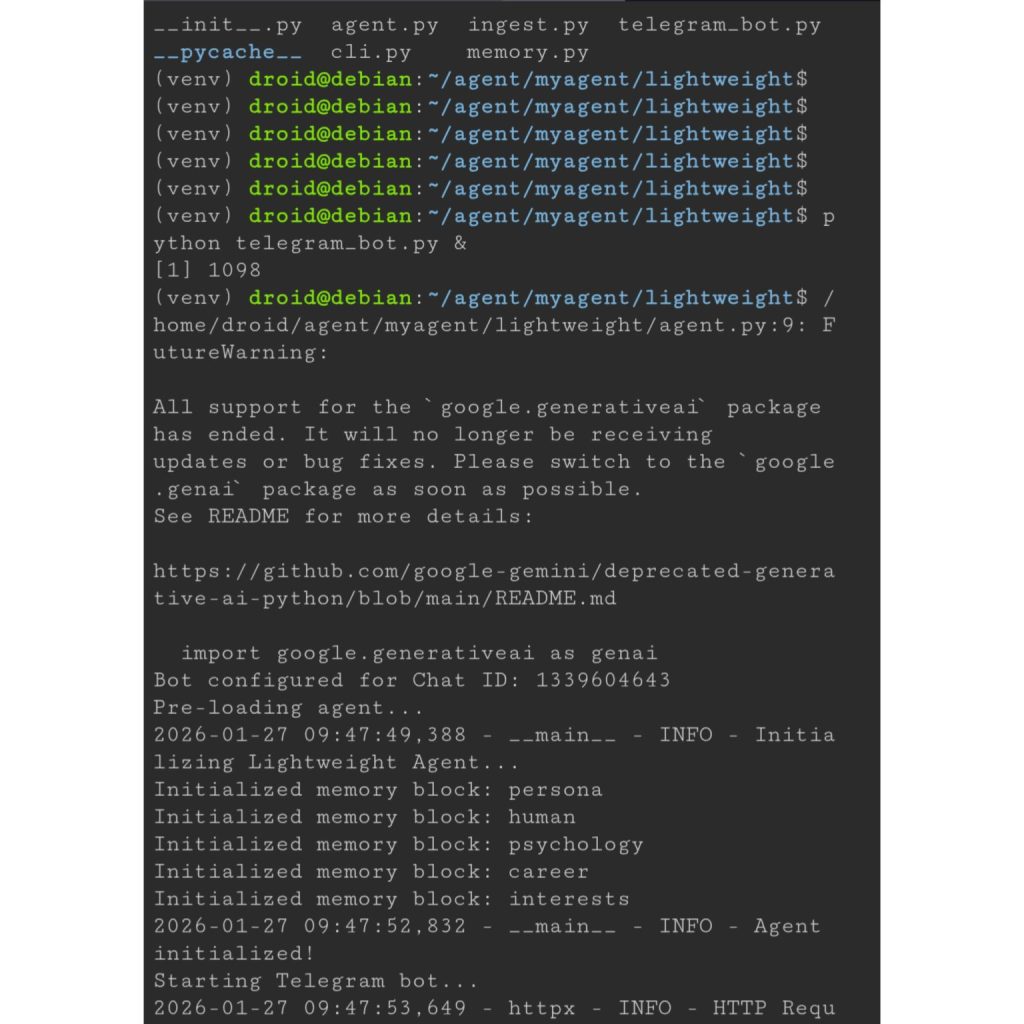
The logs show the automated execution from start to finish:
2026-06-28 20:19:38 [INFO] Fetching telemetry for Mt. Nyiragongo...
2026-06-28 20:19:39 [INFO] Elevated alert level YELLOW for Mt. Nyiragongo. Fetching satellite image...
2026-06-28 20:19:43 [INFO] HTTP Request: GET https://earthengine.googleapis.com/v1/.../thumbnails/...:getPixels "200 OK"
2026-06-28 20:19:44 [INFO] Successfully annotated and saved volcano image for Mt. Nyiragongo.
2026-06-28 20:19:46 [INFO] Telegram alert with photo sent successfully for Mt. Nyiragongo.
Why This Was Fun
By combining high-cadence thermal monitoring with high-resolution multispectral imagery on-demand, this architecture built my first smart, resource-efficient remote sensing agent.
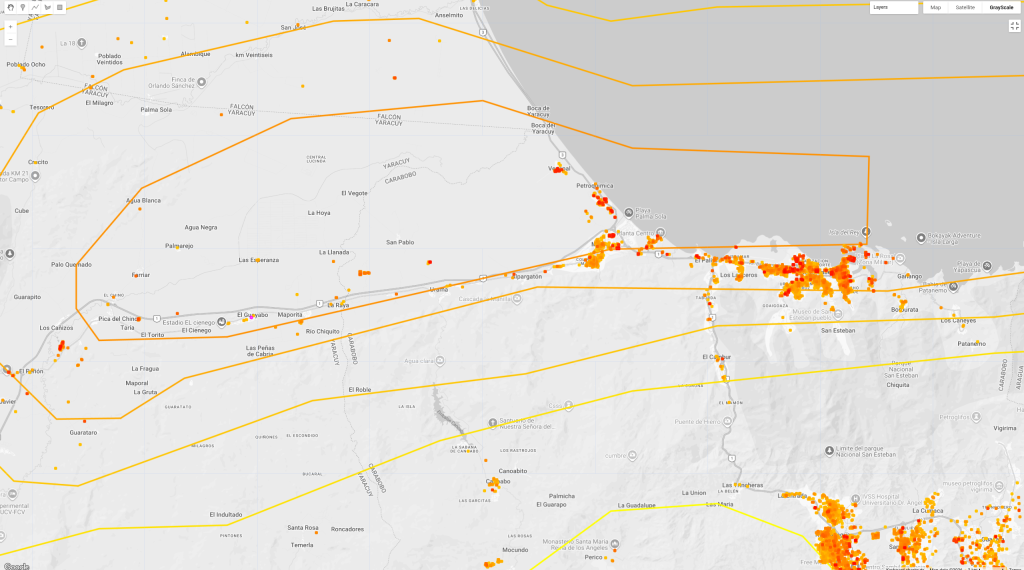
On June 24, 2026, northern Venezuela was struck by a powerful pair of consecutive earthquakes, a major M7.2 foreshock followed closely by a massive M7.5 mainshock. When disasters of this scale hit, the immediate question for responders and researchers is always the same: Where is the population most severely impacted?
To answer this, I wanted to build a rapid visual assessment tool. In this post, I’ll walk through how I mapped the USGS ShakeMap shaking intensity contours directly over the Google Open Buildings dataset using Google Earth Engine (GEE).
As someone who was proud to work on the Google Open Buildings project, it’s still amazing to see the potential impact of the dataset now over three years old. (V1 is from 2023)
Ingesting the Seismic Data
I parsed the official USGS GeoJSON contours for both events and loaded them into GEE.
Dual-Scale Building Visualizations
I used the Google Open Buildings Temporal V1 dataset (specifically using the 2023 mosaic) and split the representation into two layers:
Regional Scale (Heatmap): A smooth settlement density heatmap generated
Local Scale (Footprints): Diliated building footprints and height rasters.
Key Takeaway: Morón and Puerto Cabello
The epicenters of both the M7.2 and M7.5 events were located right on the coast of the Carabobo state. When overlaying the building density hotspots, Morón and Puerto Cabello stand out as the two largest and most vulnerable urban centers directly within the highest shaking intensity zones. Puerto Cabello’s dense port infrastructure and residential zones align with the peak acceleration contours.
This took several years and I’m so happy it is finally out. We just released an open-source dataset of nearly 2M African speech records for speech recognition and vocalization (27 languages). As of today it already has close to 10k downloads and it is currently being used for ASR and TTS AI models training.
Fun experiment: I built a personalized AI agent that lives on my phone, running inside the Linux Terminal app (pixel phones only for now). I’m fascinated by AI agents and memory systems, so I integrated a lightweight database to track my digital life. It learns from my social media activity, my code, website, CV, and even my Google Scholar page. The goal is for the agent to proactively fetch tailored content (e.g., AI/ML research). It communicates via Telegram and runs on a schedule via Python’s built-in asyncio library. It leverages the Gemini API and local models for tasks like searching or quizzing me. A feature I already love: asking the agent to summarize my Bluesky feed based on my interests. Who knows, it may even reduce downscrolling! 📉.
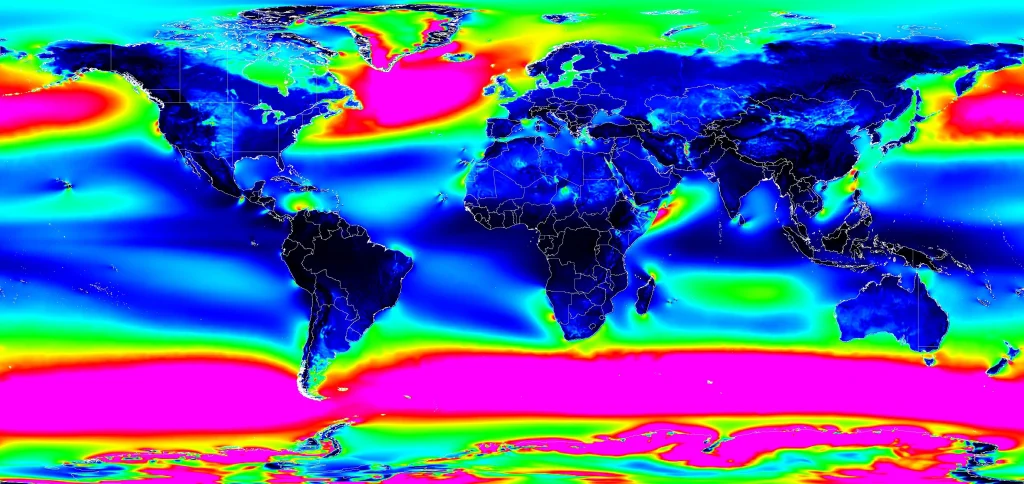
Until a few days ago, I hadn’t. I was exploring WeatherNext-2—an experimental AI weather forecasting model—when I stumbled upon something striking along the coast of East Africa. The visualization below shows global wind power potential at 100 meters (typical wind turbine height) forecasted by the model for 2025.
Global Wind Power Potential(100m) – 2025 (Experiment metric: Wind power density)
It looks like a jet engine shooting out of the Horn of Africa. A quick search confirmed this is the “Somali Jet,” a well-documented low-level atmospheric phenomenon.
But here’s what fascinated me: The AI model reproduced and forecast this jet stream without ever being explicitly programmed with the physics of fluid dynamics. It discovered this feature by learning from 40 years of historical weather data.
Going through this dataset made me feel we are going through a special moment—something noteworthy is happening in atmospheric science, and it’s worth understanding why.
The “AlphaGo” Moment for Weather forecasting
For decades, meteorology has relied on Numerical Weather Prediction (NWP). Scientists encode the fundamental laws of physics—how air pressure, temperature, humidity, and wind interact—into massive computer simulations. These models divide the atmosphere into millions of grid cells and calculate how conditions in each cell evolve over time. It’s amazing science and research, but it requires enormous computational resources. Running a global weather forecast on traditional systems is like playing chess by calculating every possible future position, it’s computationally expensive.
Learning from History
WeatherNext-2 represents a different approach, powered by a technique called FGN (Functional Generative Networks). Instead of being programmed with physics equations, the model learned atmospheric dynamics by “studying” patterns in 40 years of historical weather data.
Rather than teaching a computer the rules of chess and having it calculate moves, imagine showing it millions of chess games and letting it discover winning strategies on its own. That’s the shift happening in weather forecasting.
FGN outperforms the previous state-of-the-art ML model (GenCast) while providing an extra 24 hours of lead time for tracking tropical cyclones. That extra day can make a big difference to prepare.
Computational Efficiency: Despite being a larger model than GenCast, FGN generates a 15-day forecast in under 1 minute on a single TPU, 8 times faster than GenCast. This is because it requires only a single forward pass through the network, unlike diffusion models that need iterative refinement.
To put it simply, the model understands that the atmosphere is deeply interconnected—that the pressure in Dakar is linked to conditions in Nairobi. It learned from observing how weather patterns actually flow across our continent and around the world.
What Makes FGN Different
Traditional ML weather models predict a single “most likely” outcome. FGN generates ensembles—64 different plausible scenarios for how weather might evolve.
What is fascinating is that FGN learned to produce these realistic probability distributions while being trained only to minimize error at individual locations (what researchers call “marginal distributions”). It wasn’t explicitly taught about spatial correlations or how different weather variables relate to each other—it discovered these relationships on its own.
To put it simply, imagine a Council of Four Grandmasters that work together to map out all the possibilities of a chess game. FGN in production employs 4 expert models to provide 64 distinct potential futures (an ensemble). This allows us to see the full range of risks—all generated in under one minute on a single TPU.
The “Clever Trick” To prevent the “blurriness” common in generative AI, WeatherNext-2 employs a Graph Transformer that injects a shared noise vector to enforce physical consistency across the globe. Imagine a conductor’s baton used to lead a symphony: this architecture allows complex global patterns (joint structure) to emerge naturally, enabling the model to master the entire planet’s weather despite being trained solely on individual locations.
A side note: If I had to pick a word for 2025, it would be “ensemble”. Ensemble forecasts, ensemble of models, mixture of experts— feels like a pattern. Diverse, specialized components working together beat singular “optimal” solutions. Four weather models trained independently outperform one perfect model.
Key Innovation: FGN generates probability distributions for weather forecasts by modeling both epistemic uncertainty (what we don’t know about the model) and aleatoric uncertainty (the inherent randomness in weather) through learned variations in the neural network’s parameters.
For those who want to hear about the research and the evolution of these models, I highly recommend this video by my colleague and one of the lead authors Ferran Alet Puig , as well as the original paper.
The WeatherNext-2 dataset acts as a massive archive of forecasts, generating new 15-day predictions every 6 hours. It’s accessible through Google Earth Engine, BigQuery, and as raw data files (you need to apply to get access).
The data includes:
Surface Variables: Temperature, precipitation, wind speed and direction at 10m and 100m above ground
Atmospheric Variables: Humidity, geopotential (related to altitude and pressure), and wind vectors at 13 different pressure levels throughout the atmosphere
Ensemble Predictions: 64 different scenarios for each variable, allowing us to calculate probabilities and confidence intervals
Data info: The model is trained on 40 years of historical weather data from ECMWF (1979-2022), using ERA5 reanalysis for pre-training and more recent operational data for fine-tuning.
Important note: Visualizations in this post are AI predictions, not observations of reality. I’m someone in research exploring geospatial data, not a climate scientist. Always refer to official meteorological agencies for actionable weather information.
Experiments: Exploring What the Model Reveals
1. Wind Energy Potential: From the Somali Jet to Global Patterns
The Somali Jet discovery got me curious: Where else might significant wind energy potential exist that we haven’t fully recognized?
Since the dataset includes wind speeds at 100 meters—the typical hub height for modern wind turbines—I combined this with the Google Open Buildings dataset to create theoretical infrastructure analyses. I simulated how a single industrial wind turbine could potentially serve households within a 5-kilometer radius.
The results surprised me.
Beyond well-known locations like the UK and South Africa, the model highlighted promising potential in:
The Mauritanian coast
Central Sahara in Chad
The coast of Somalia
Barranquilla, Colombia
Traditional wind resource assessment requires deploying expensive LIDAR equipment for up to a year at each potential site. While AI models can’t replace ground-truthing, they could dramatically reduce the search space for where to invest in detailed surveys—particularly valuable for developing regions with limited resources.
Note: These are exploratory visualizations based on forecasted wind patterns, not engineering assessments. Actual wind farm development requires detailed on-site measurements, environmental impact studies, and grid integration analysis.
2. Atmospheric Rivers: Visualizing Invisible Water Highways
Atmospheric rivers are narrow corridors of concentrated water vapor in the atmosphere—essentially rivers in the sky. When they make landfall, they can deliver enormous amounts of precipitation in a short time, causing both beneficial water supply and devastating floods.
Because FGN’s forecasts include both wind vectors and moisture data, I attempted to visualize these phenomena. The results were mesmerizing—you can see moisture being transported across entire ocean basins in streams.
Understanding and predicting atmospheric rivers is critical for water resource management and flood preparedness.
3. Storm Tracking: Melissa and Typhoon Fung-Wong
To evaluate the model’s forecasting performance, I compared its predictions against actual tropical cyclone tracks from 2025.
The animations below show Storm Melissa and Typhoon Fung-Wong, with the AI’s forecast tracks (generated days in advance) plotted against the actual paths recorded by the International Best Track Archive for Climate Stewardship (IBTrACS).
Important note: While FGN shows measurable improvements over previous models—specifically that 24-hour advantage in cyclone tracking lead time—all forecasting systems become less accurate as lead time increases. Weather is chaotic, and even the best models have uncertainty limits.
I also used the dataset to visualize significant weather events from 2025.
European Heatwaves: I was actually in London during the summer heatwave, visiting from Ghana. Seeing people walking around with mini-fans was surreal—and the model had captured this moment in its forecasts.
African Heat Patterns: I was also keen to vizualize the model’s forecasts of high-temperature events (above 35°C) across Africa to see seasonal patterns and localized extreme heat events. Understanding the predictability of these conditions could help with things such as agricultural planning.
Wind and Rain Patterns: This final visualization shows the interplay of winds and rainfall that shaped weather across the globe in 2025. The blue-to-orange gradient represents wind intensity, while the neon glow highlights precipitation.
My take away from this exploration
We are entering an era where high-resolution, probabilistic forecasting will not necessarily require supercomputing resources. This changes the economic calculus for regions like East Africa—whether that means better storm preparedness or identifying untapped wind potential in the Sahel.
For centuries, we have modeled the world by understanding the rules first, then simulating them. This model does the inverse: it observes the output (the weather) and infers the dynamics, effectively “rediscovering” features like the Somali Jet without ever seeing a physics equation.
If an AI can empirically derive the laws of fluid dynamics without the theoretical equations, what does this mean for modeling other complex systems?
There are obvious limits—these models can’t explain why something works in human-interpretable terms. But could this data-driven approach complement theoretical physics in powerful ways?
It is genuinely inspiring to witness the profound shift my colleagues are driving in how we understand our planet.
A Personal Note: The Changing Nature of Technical Work
There’s another layer to this story worth sharing.
Back at PyCon Africa 2022, I gave a talk about AI-assisted coding. I knew it was coming, but I had no idea how quickly it would transform my personal workflow.
A year ago, producing the visualizations for this post—writing the Earth Engine logic & code, debugging the vector mathematics, and fine-tuning the palettes—would have taken me weeks if not more. For this post, I iterated with Gemini to generate 80% of the code.
To be clear, it wasn’t magic. I still had to intervene quite a few times e.g fixing the code or catching “hallucinations”. But what used to be a weeks-long “project” became a fun afternoon of debugging and curation.
As we look toward 2026, I believe you will see this across many fields. Software engineers have always carried a toolkit, but that toolkit just got an upgrade. From agent frameworks to AI coding assistants, the friction now lies in mastering these new instruments and the environment.
The Paradox of Easier Code Generation
Even with AI generating code much faster than I could write it manually, software engineering principles have never been more important. When you can generate hundreds of lines in an afternoon instead of weeks, the discipline to structure, test, document, and maintain that code becomes critical. The code comes faster, but the thinking can’t be rushed. You still need to know what to build, how it should be architected, why certain approaches are better than others (e.g cost, performance,etc..) and have a plan to maintain it. It feels like we’re moving from a constraint on capability to a constraint on curiosity and judgment. The bottleneck is no longer “can I build this?” but “which solution should I select?”.
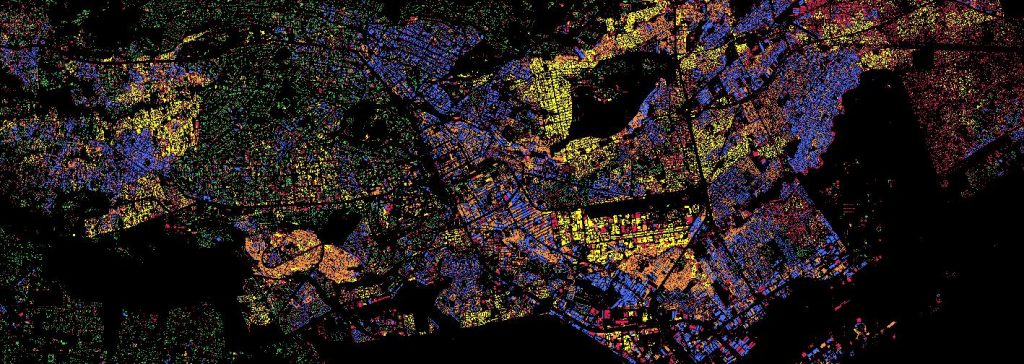
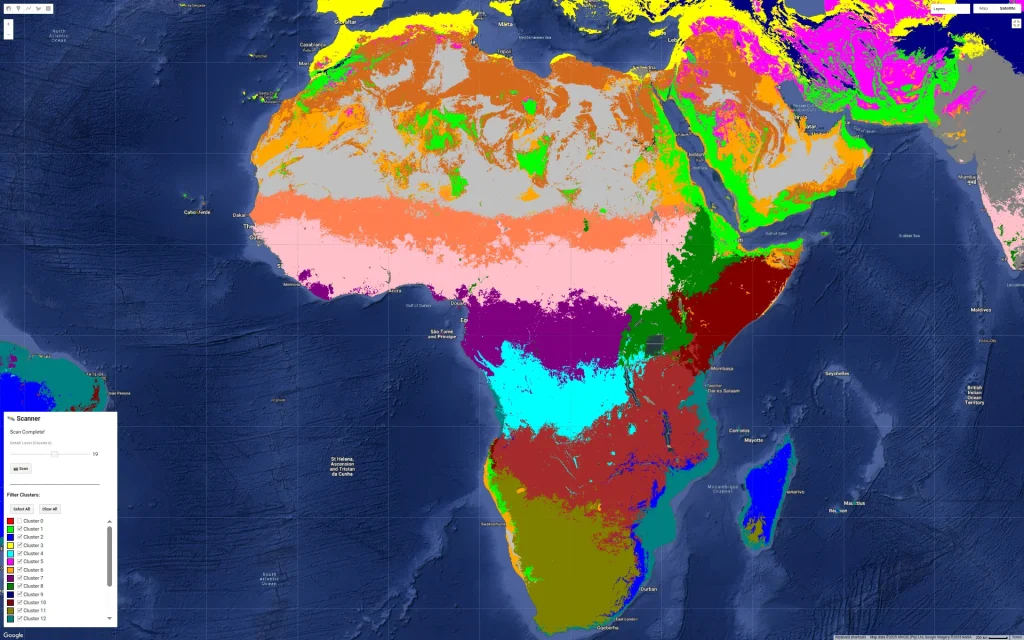
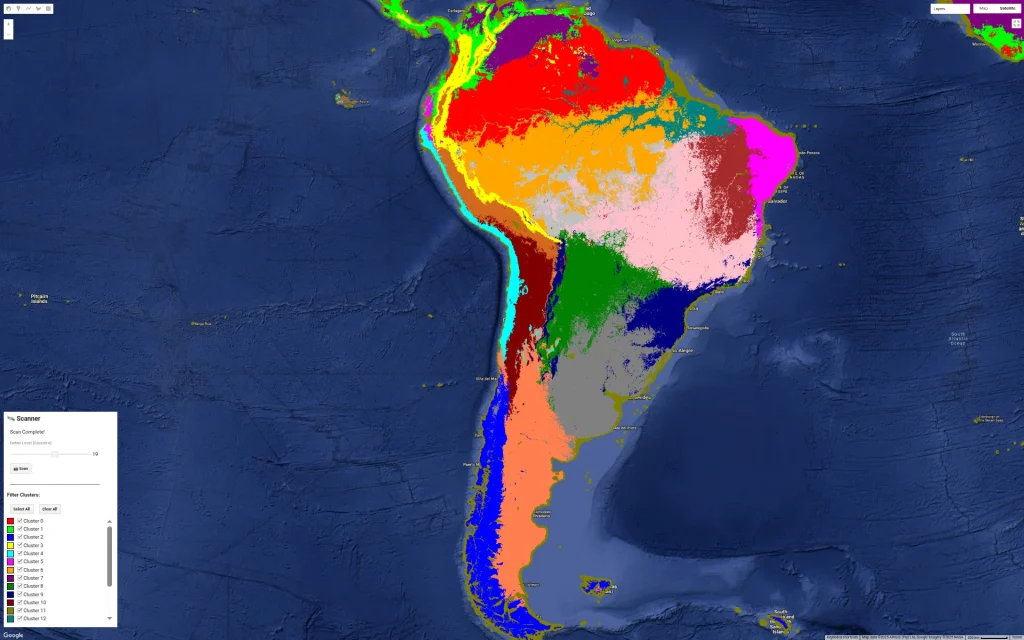
I’ve been experimenting with a fun way to visualize urban density by mixing the Google Open Buildings dataset with AlphaEarth embeddings. I’m using unsupervised clustering on top of AlphaEarth’s embeddings. Instead of coloring pixels for each area, I’ve assigned the cluster color to the building polygons themselves. The result is an interesting “fingerprint” of these cities. The clustering logic is still a bit of a mystery tobe honest, it could be picking up on building materials, street orientation, or height ect.. In some case it is just picking water bodies or green spaces. Anyway it reveals patterns that would be hard to see from a satellite image. One takeaway I have from looking at many African cities so far is the lack of green spaces which is not a secret but very visible… I am also sharing screenshots of clustering on continents and major cities but without the buildings.
// Google Open Buildings v3 view with AlphaEarth embeddings
// Experimental script - CCBY4
// --- 1. DYNAMIC GEOMETRY ---
// How to use it: Choose your current view on the map and click run
// --- 1. CAPTURE THE VIEW ---
var bounds = Map.getBounds(true);
var cityROI = ee.Geometry(bounds);
// --- 2. DATA LOADING (LOCKED TO 2023) ---
var alphaEarth = ee.ImageCollection("GOOGLE/SATELLITE_EMBEDDING/V1/ANNUAL")
.filterBounds(cityROI)
.filter(ee.Filter.date('2023-01-01', '2023-12-31'))
.first()
.clip(cityROI);
var buildings25D = ee.ImageCollection('GOOGLE/Research/open-buildings-temporal/v1')
.filterBounds(cityROI)
.filter(ee.Filter.eq('inference_time_epoch_s', 1688108400))
.mosaic()
.clip(cityROI);
var buildingPresence = buildings25D.select('building_presence');
// --- 3. SURGICAL TRAINING (BUILDINGS ONLY) ---
// We mask AlphaEarth BEFORE sampling so the trainer ONLY sees building signatures.
var buildingMask = buildingPresence.gt(0.2);
var alphaOnlyBuildings = alphaEarth.updateMask(buildingMask);
var training = alphaOnlyBuildings.sample({
region: cityROI,
scale: 10, // Native resolution for high precision
numPixels: 5000,
tileScale: 16,
dropNulls: true // CRITICAL: This ignores non-building pixels
});
// Train Clusterer on the BUILDING signatures only
var clusterer = ee.Clusterer.wekaKMeans(6).train(training);
// Apply that "Building-Logic" to the whole city
var allClusters = alphaEarth.cluster(clusterer);
// Final visualization mask
var finalClusters = allClusters.updateMask(buildingMask);
// --- 4. VISUALIZATION ---
var clusterPalette = ['#e6194b', '#3cb44b', '#ffe119', '#4363d8', '#f58231', '#911eb4'];
var blackBackground = ee.Image(0).visualize({palette: ['#000000']});
Map.addLayer(blackBackground, {}, '1. Black Background');
Map.addLayer(finalClusters, {min: 0, max: 5, palette: clusterPalette}, '2. Surgical Building Clusters');
// --- 5. EXPORT ---
Export.image.toDrive({
image: finalClusters.visualize({min: 0, max: 5, palette: clusterPalette}),
description: 'ROI_2023_Building_Clusters',
scale: 10,
region: cityROI,
fileFormat: 'GeoTIFF',
maxPixels: 1e13
});
This was sobering forecast for 𝐇𝐮𝐫𝐫𝐢𝐜𝐚𝐧𝐞 𝐌𝐞𝐥𝐢𝐬𝐬𝐚 on Google DeepMind’s experimental Weather Lab. (Seen on Sunday 26th, 2025)
The AI model’s ensemble predicted with high confidence the devastating track: CAT 4 landfall in 𝐉𝐚𝐦𝐚𝐢𝐜𝐚 (around Tuesday, Oct 28th) [Turned out it was a CAT 5], followed by a CAT 3 impact on Cuba (Wednesday, Oct 29th).
Google DeepMind and UCL experts have released a 𝗳𝗿𝗲𝗲, hands-on curriculum. It covers the fundamentals of building and fine-tuning language models, including data preparation, neural networks, and the transformer architecture.
Here’s a look at what the courses cover:
𝗕𝘂𝗶𝗹𝗱 𝗬𝗼𝘂𝗿 𝗢𝘄𝗻 𝗦𝗺𝗮𝗹𝗹 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗠𝗼𝗱𝗲𝗹: Learn the fundamentals of LMs, from traditional n-grams to modern transformers.
𝗥𝗲𝗽𝗿𝗲𝘀𝗲𝗻𝘁 𝗬𝗼𝘂𝗿 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗗𝗮𝘁𝗮: Dive deep into preparing text data with tokenization and embeddings.
𝗗𝗲𝘀𝗶𝗴𝗻 𝗔𝗻𝗱 𝗧𝗿𝗮𝗶𝗻 𝗡𝗲𝘂𝗿𝗮𝗹 𝗡𝗲𝘁𝘄𝗼𝗿𝗸𝘀: Understand the training process, how to spot overfitting, and implement neural networks.
𝗗𝗶𝘀𝗰𝗼𝘃𝗲𝗿 𝗧𝗵𝗲 𝗧𝗿𝗮𝗻𝘀𝗳𝗼𝗿𝗺𝗲𝗿 𝗔𝗿𝗰𝗵𝗶𝘁𝗲𝗰𝘁𝘂𝗿𝗲: Explore the mechanisms of transformers, including the all-important attention mechanism.
𝗧𝗿𝗮𝗶𝗻 𝗮 𝗦𝗺𝗮𝗹𝗹 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗠𝗼𝗱𝗲𝗹 (𝗖𝗵𝗮𝗹𝗹𝗲𝗻𝗴𝗲 𝗟𝗮𝗯): Apply everything you’ve learned in a final challenge to build a character-based model from scratch.
This is one of the most interesting (and hilarious) stories I’ve heard this year. A competitor in a major RNA folding competition lacked GPU access. This “GPU poor” competitor had to innovate, and they ended up beating everyone. (2400 participants) How? Pure engineering and ingenuity. Instead of tackling the problem with a very large AI model, they were forced to be smarter. They built a complex data pipeline that just… achieved better results. The focus was on data quality and better algorithms. The method used was a TBM data pipeline (1990s tech…). 💀 Now, the officially winning solution was a hybrid. But the real story is that a heavy, data-centric approach can still out-innovate a pure AI one. This was RNA folding (not protein folding), a problem with a much smaller dataset, and the “classic” method won. The author even mentions in the comments that the original pipeline had no AI at all and a better score. They technically won despite AI. 😂
There are so many lessons here, but the main ones are: AI is not always the solution. 𝑁𝑒𝑐𝑒𝑠𝑠𝑖𝑡𝑦 𝑖𝑠 𝑡ℎ𝑒 𝑚𝑜𝑡ℎ𝑒𝑟 𝑜𝑓 𝑖𝑛𝑣𝑒𝑛𝑡𝑖𝑜𝑛, as you may have heard. My main takeaway, though? If you are a researcher in a low-resource setting, know that you can compete. You can win by being more 𝑟𝑒𝑠𝑜𝑢𝑟𝑐𝑒𝑓𝑢𝑙. The solution and must read: Stanford- RNA 3D Folding competition solution write up
On the computational biology side, allow me to also plug in some important updates recently from Google:
This week, Google Research and partners (including UC Santa Cruz) released Deepsomatic, an AI tool that identifies cancer-related mutations in a tumor’s genetic sequence to help pinpoint what’s driving the cancer. Deepsomatic
The AlphaFold Database has been updated with new data and functionalities, continuing its partnership with Google DeepMind and EMBL-EBI. Alaphafold DB
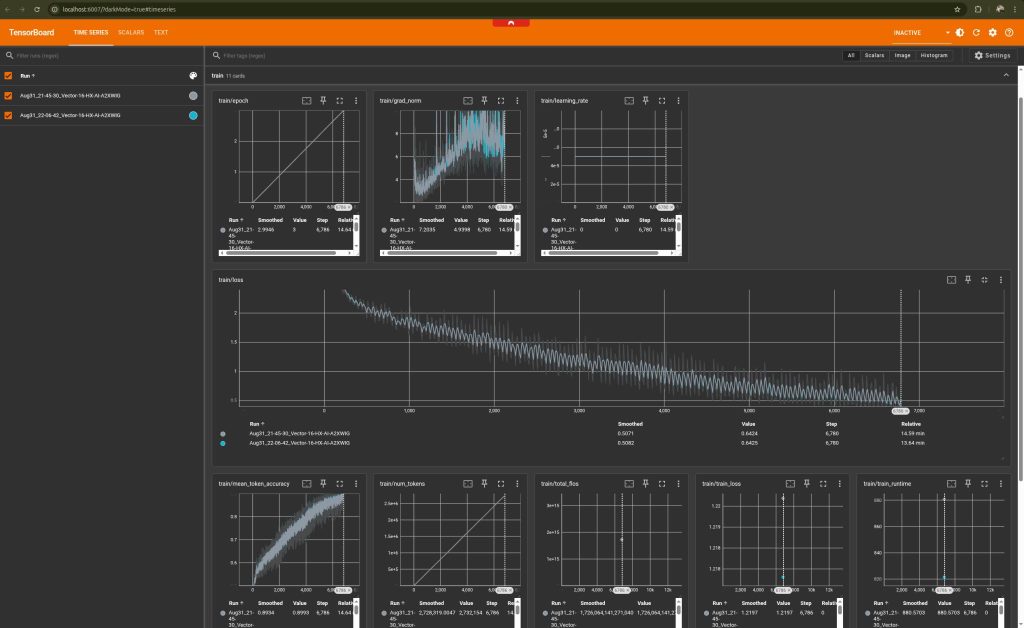
Fun Sunday exercise, how much useful information I can squeeze in a tiny AI model. My goal was to take a general-purpose language model and turn it into an expert on a topic vital such as agriculture.
Here are my steps:
1. The Foundation: Google’s Gemma 270M
I started with this small but powerful but compact base model, gemma-3-270m-it. At just 550 MB, it’s a brilliant piece of engineering that can run on consumer-grade hardware.I am using my laptop.
2. The Technique: Parameter-Efficient Fine-Tuning (PEFT) with LoRA
Instead of retraining the entire model (which is slow and resource-intensive), I used a technique called LoRA. Think of it like adding a small, highly specialized “expert module” to the model’s existing brain. The original model’s knowledge remains, but we efficiently “teach” it a new skill, in this case agricultural information.
3. The Curriculum: The Agriculture Q&A Dataset
I used the KisanVaani/agriculture-qa dataset to teach the model the nuances of farming, crops, pests, and soil.
After a 15m training session, the new “expert module” I created was only 45 MB! That’s right. For just 45 MB, I layered deep agricultural knowledge onto a powerful base model. This process has created a specialized AI assistant that is more accurate and relevant for agricultural queries than the original.
Model output:
— Loading Model and Tokenizer —
Model and tokenizer loaded successfully.
Dataset loaded successfully from ‘/home/abdoulaye/aiplayground/agriculture_qa_dataset’.
Device set to use cuda:0
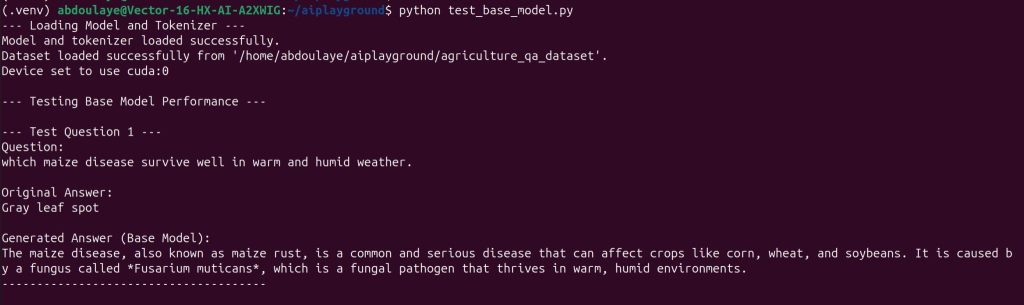
— Testing Base Model Performance —
— Test Question 1 —
Question:
which maize disease survive well in warm and humid weather.
Original Answer:
Gray leaf spot
Generated Answer (Base Model):
The maize disease, also known as the maize blight, is a fungal disease that can affect maize plants, particularly in areas with high humidity and high temperatures. It’s a common problem in many parts of the world, and it can be difficult to control.
————————————–
— Test Question 2 —
Question:
how can overuse of pesticides destroy soil nutrients?
Original Answer:
Pesticides can kill beneficial soil microorganisms and reduce soil biodiversity, which can lead to nutrient depletion and reduced soil fertility.
Generated Answer (Base Model):
Overuse of pesticides can be a serious threat to soil nutrients, which are essential for plant growth, soil health, and overall ecosystem function. Here are some ways pesticides can negatively impact soil nutrients:
* **Reduced nutrient availability:** Pesticides can disrupt the natural nutrient cycle, leading to nutrient deficiencies and reduced plant growth.
* **Soil degradation:** Pesticides can cause soil erosion, compaction, and altered soil structure, weakening the soil’s ability to retain nutrients.
* **Reduced plant health:** Pesticides can suppress plant growth, leading to stunted development, reduced yields, and increased susceptibility to disease.
* **Soil contamination:** Pesticides can contaminate soil with harmful chemicals, which can harm soil microorganisms, leading to soil degradation and reduced nutrient availability.
* **Impact on plant physiology:** Pesticides can affect plant physiology, including nutrient uptake, metabolism, and stress tolerance.
* **Altered soil pH:** Pesticides can alter soil pH, which can affect the availability of essential nutrients.
This quick experiment shows small AI models can provide practical solutions. By using efficient models like Gemma and smart techniques like LoRA, we can build tools that understand various local contexts.
The power to build specialized AI is here, and I’m excited to see what people will build in my region.
For those interested in the technical details, I used the Hugging Face Transformers library to handle the model and the PEFT library’s implementation of LoRA for efficient training. You can learn more about them at the links below:
* For the Hugging Face `transformers` library: This is the main documentation, the central hub for everything related to the library.
* For LoRA and PEFT (Parameter-Efficient Fine-Tuning): This link goes directly to the Hugging Face documentation for the peft library, which is what you used to implement LoRA.