This took several years and I’m so happy it is finally out. We just released an open-source dataset of nearly 2M African speech records for speech recognition and vocalization (27 languages). As of today it already has close to 10k downloads and it is currently being used for ASR and TTS AI models training.
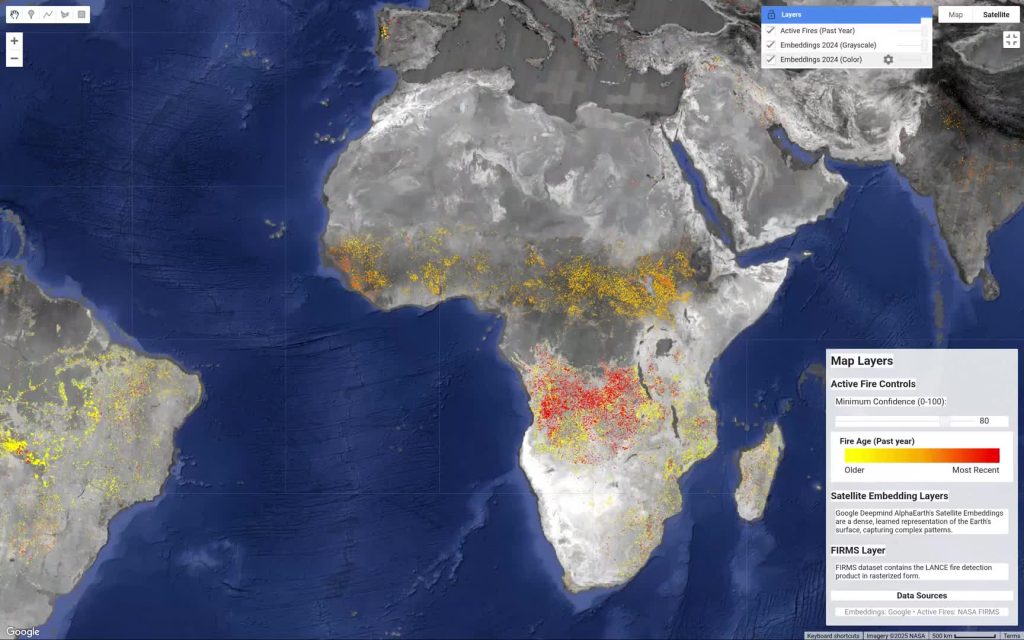
I started this exercise wondering how Google DeepMind’s AlphaEarth embeddings dataset would compare to historical fire data. It turned out to be a really interesting experience. I learned there are a lot of fires in central Africa—especially Southern DRC, Angola, and Zambia—far more than I expected. Apparently, some fires are set on purpose as part of an agricultural practice. Still, it’s worrying to see so many fires, especially when you think about the ones recently in the news across North America and Southern Europe. Funny enough, I hadn’t even noticed the pattern until my 9-year-old son pointed out the region to me while we were checking the map. I find the AlphaEarth dataset fascinating, as you can see a clear correlation between the type of landscape and where fires happen. I used Gemini to generate the boilerplate JavaScript for Google Earth Engine, and I had this visualization running in a few minutes. Gemini is quite good at generating JavaScript for Google Earth Engine.
Video caption: The colorful background is an AI’s unique “fingerprint” of our planet, where landscapes with similar characteristics get similar colors. Overlaid on top, the yellow/orange/red dots are real fire hotspots detected by NASA satellites over the last year with a confidence level set at 80%.
Video caption: The colorful background is an AI’s unique “fingerprint” of our planet, where landscapes with similar characteristics get similar colors. Overlaid on top, the yellow/orange/red dots are real fire hotspots detected by NASA satellites over the last year with a confidence level set at 80%.
(Note: This post reflects my personal opinions and may not reflect those of my employer)
Example of the HeAR encoder that generates a machine learning representation (known as “embeddings”)
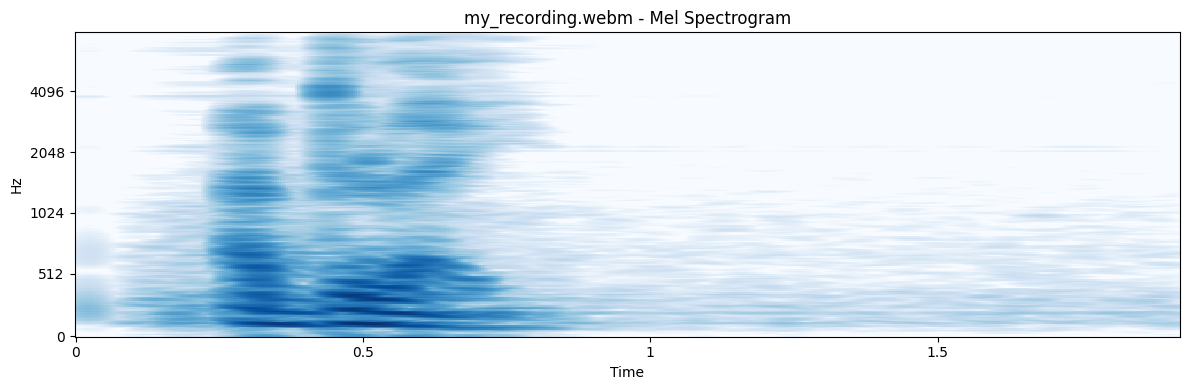
This image is a spectrogram representing my name, “Abdoulaye,” generated from my voice audio by HeAR (Health Acoustic Representations). HeAR is one of the recently released Health AI foundation models by Google. I’ve been captivated by these foundation models lately, spending time digging into them, playing with the demos and notebooks, reading ML papers about the models, and also learning more about embeddings in general and their usefulness in low-resource environments. All of this started after playing with a couple of the notebooks.
Embeddings are numerical representations of data. AI models learn to create these compact summaries (vectors) from various inputs like images, sounds, or text, capturing essential features. These information-rich numerical representations are useful because they can serve as a foundation for developing new, specialized AI models, potentially reducing the amount of task-specific data and development time required. This efficiency is especially crucial in settings where large, labeled medical datasets may be scarce.
If you would like to read further into what Embeddings are, Vicki Boykis’ essay is such a great free resource; this essay is also ideal to learn or dive into machine learning. I know many of my previous colleagues from the telco and engineering world will love this: https://vickiboykis.com/what_are_embeddings/
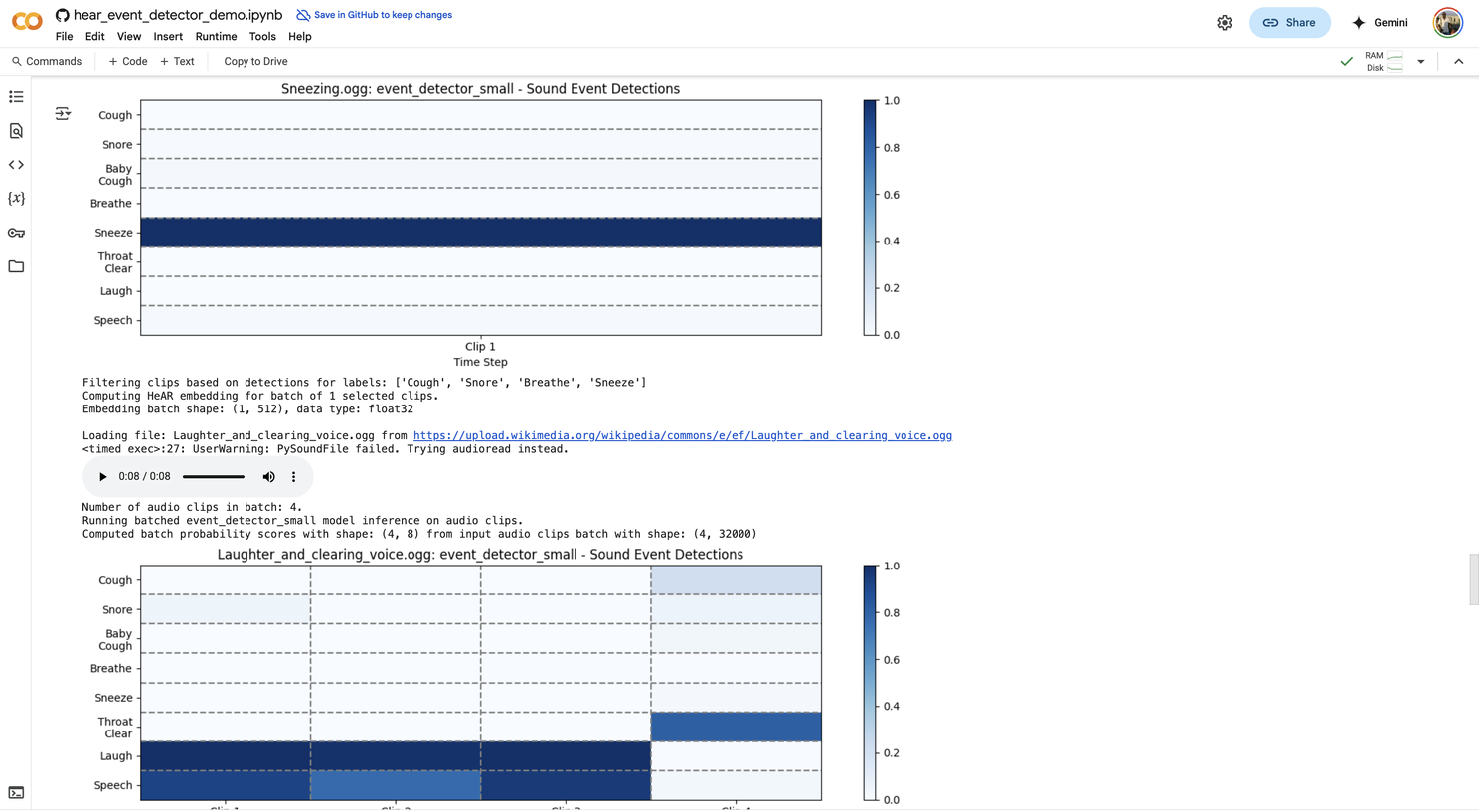
The HeAR model, which processed my voice audio, is trained on over 300 million audio clips (e.g., coughs, breathing, speech). Its application can extend to identifying acoustic biomarkers for conditions like TB or COVID-19. It utilizes a Vision Transformer (ViT) to analyze spectrograms. Below, you can see an example of sneezing being detected within an audio file, and later, throat clearing detected at the end.
This release also includes other open-weight foundation models, each designed to generate high-quality embeddings:
Derm Foundation (Skin Images) This model processes dermatology images to produce embeddings, aiming to make AI development for skin image analysis more efficient by reducing data and compute needs. It facilitates the development of tools for various tasks, such as classifying clinical conditions or assessing image quality.
Explore the Derm Foundation model site for more information and to download the model use this link.
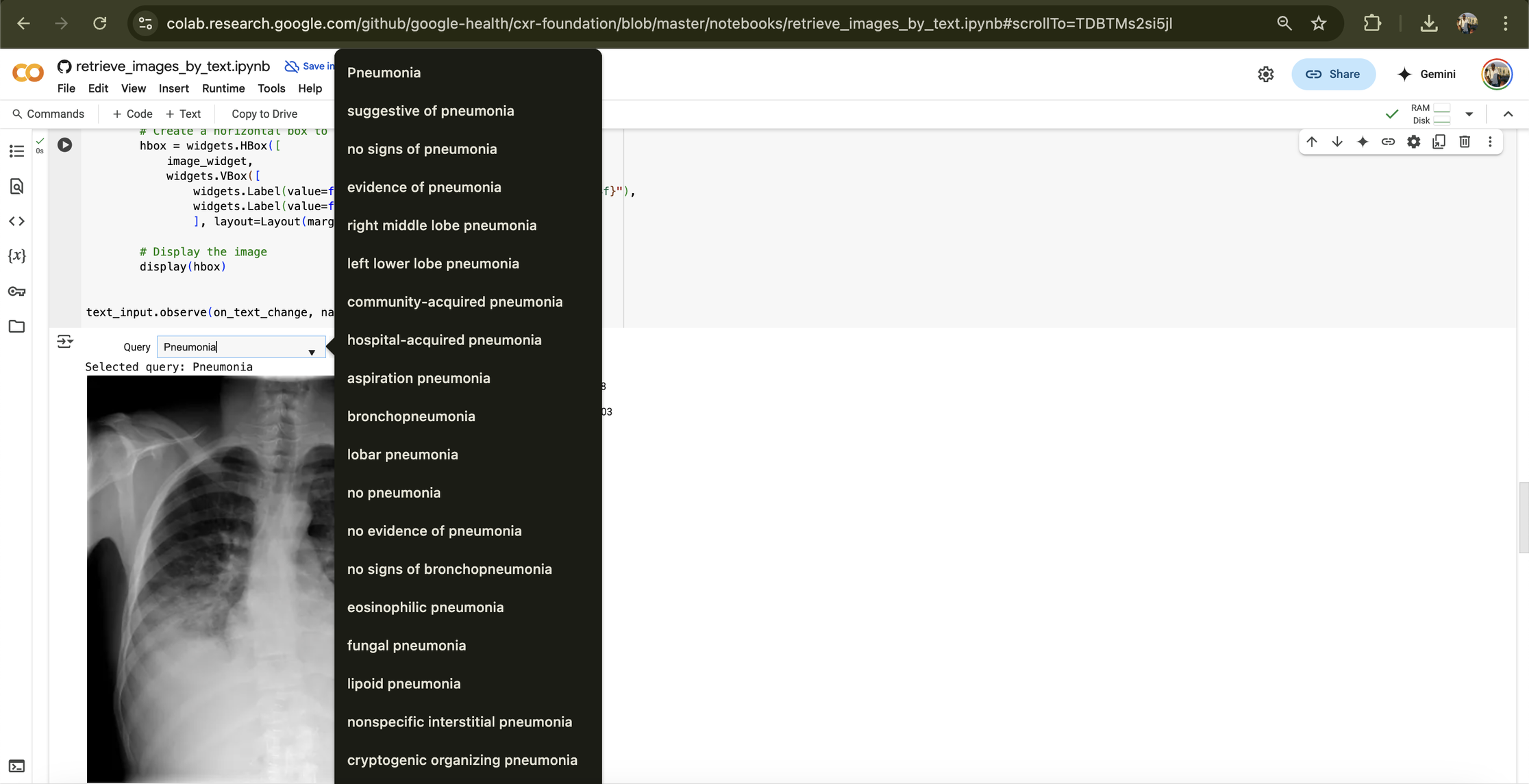
CXR Foundation (Chest X-rays) The CXR Foundation model produces embeddings from chest X-ray images, which can then be used to train models for various chest X-ray related tasks. The models were trained on very large X-ray datasets. What got my attention, some models within the collection, like ELIXR-C, use an approach inspired by CLIP (contrastive language-image pre-training) to link images with text descriptions, enabling powerful zero-shot classification. This means the model might classify an X-ray for a condition it wasn’t specifically trained on, simply by understanding a text description of that condition which i find fascinating. The embeddings generated can also be used to train models that can detect diseases like tuberculosis without a large amount of data; for instance, “models trained on the embeddings derived from just 45 tuberculosis-positive images were able to achieve diagnostic performance non-inferior to radiologists.” This data efficiency is particularly valuable in regions with limited access to large, labeled datasets. Read the paper for more details.
Path Foundation (Pathology Slides) Google’s Path Foundation model is trained on large-scale digital pathology datasets to produce embeddings from these complex microscopy images. Its primary purpose is to enable more efficient development of AI tools for pathology image analysis. This approach supports tasks like identifying tumor tissue or searching for similar image regions, using significantly less data and compute. See the impressive Path Foundation demos on HuggingFace.
Path foundation demos
Outlier Tissue Detector Demo
These models are provided as Open Weight with the goal of enabling developers and researchers to download and adapt them, fostering the creation of localized AI tools. In my opinion, this is particularly exciting for regions like Africa, where such tools could help address unique health challenges and bridge gaps in access to specialist diagnostic capabilities.
For those interested in the architectural and training methodologies, here are some of the pivotal papers and concepts relevant to these foundation models:
Vision Transformer (ViT): Applied in HeAR and Path Foundation. (An Image is Worth 16×16 Words: https://arxiv.org/abs/2010.11929)
Masked Autoencoders (MAE): A self-supervised learning technique used for HeAR. (Masked Autoencoders Are Scalable Vision Learners: https://arxiv.org/abs/2111.06377)
EfficientNet: The family of architectures related to the backbone for CXR Foundation models. (EfficientNet: https://arxiv.org/pdf/1905.11946)
Google Translate has taken a significant step towards greater inclusivity by adding 110 new languages to their service, including 31 from Africa. This expansion means that millions of people who previously lacked access to translation services now have a tool to communicate and connect with a wider world.
This achievement is the result of a concerted multi years effort by Isaac Caswell, the Google Translate Research team, and numerous community collaborators. They faced unique challenges, as building high-quality translations for languages with limited digital resources is complex. To address this, they developed an approach that relies on “monolingual” data – text in a single language – instead of solely relying on translated text. This method, called “zero-shot learning,” allows for the creation of translations for languages not explicitly trained on, though it’s important to remember that this is still a developing technology.
What does this mean?
More Accessibility: People speaking these newly included languages now have a tool to access information, communicate, and break down language barriers.
Language Preservation: This expansion helps preserve and promote less commonly used languages, which is crucial for maintaining linguistic diversity.
New Opportunities: The inclusion of languages like Punjabi and Romani opens doors for those communities, aiding in digital navigation and accessing information.
While this is a significant step, it’s important to note that Google Translate, while utilizing powerful AI technology, is not a replacement for the expertise of professional translators, however the app is useful for millions of people. This new approach, powered by the Palm 2 language model will require ongoing refinement and feedback to improve accuracy.
The languages added are significant:
A few notables ones:
Punjabi (Shahmukhi): This language, written in the Shahmukhi script, is spoken by millions in Pakistan and India. Its inclusion expands communication and access to information for a large community.
Romani: Romani, the language of romani communities with presence in many european countries, has historically been underrepresented in technology. Its inclusion in Google Translate is a step towards recognizing and supporting this community.
N’ko: Created in the 1940s, N’ko uses a unique script to unify Manding languages in West Africa. This addition supports literacy and cultural preservation efforts.
Tamazight (with Tifinagh script): Tamazight is spoken by millions of Berber people in North Africa. Its inclusion acknowledges their cultural diversity and language heritage.
This expansion is a positive step towards a more inclusive digital world, but it’s important to be aware of its limitations. While AI is an exciting tool, it requires continual development and feedback to refine its capabilities. The addition of these new languages is a testament to the potential of technology to foster communication and understanding, but it’s crucial to remember that it’s a journey, not a destination.